Einführung in die Datenverarbeitung¶
Der Data Processing Service Controller ist verantwortlich für die Erstellung, Pflege und Zerstörung von Instanzen, die für seine Cluster erstellt wurden. Der Controller verwendet den Networking-Dienst, um Netzwerkpfade zwischen sich und den Cluster-Instanzen herzustellen. Es wird auch die Bereitstellung und den Lebenszyklus von Benutzeranwendungen verwalten, die auf den Clustern ausgeführt werden sollen. Die Instanzen innerhalb eines Clusters enthalten den Kern einer Verarbeitungsmaschine eines Frameworks und der Data Processing Service bietet mehrere Möglichkeiten zum Erstellen und Verwalten der Verbindungen zu diesen Instanzen.
Datenverarbeitungsressourcen (Cluster, Jobs und Datenquellen) werden durch Projekte getrennt, die im Identitätsdienst definiert sind. Diese Ressourcen werden in einem Projekt geteilt und es ist wichtig, die Zugangsbedürfnisse derjenigen zu verstehen, die den Dienst nutzen. Aktivitäten im Rahmen von Projekten (z.B. Starten von Clustern, Hochladen von Aufträgen etc.) können durch den Einsatz rollenbasierter Zugriffskontrollen weiter eingeschränkt werden.
In diesem Kapitel diskutieren wir, wie wir die Bedürfnisse der Datenverarbeitungsbenutzer hinsichtlich ihrer Anwendungen, der von ihnen verwendeten Daten und ihrer erwarteten Fähigkeiten innerhalb eines Projekts beurteilen können. Wir werden auch eine Reihe von Härtungstechniken für den Service-Controller und seine Cluster vorstellen und Beispiele für verschiedene Controller-Konfigurationen und Benutzerverwaltungsansätze bieten, um ein angemessenes Maß an Sicherheit und Privatsphäre zu gewährleisten.
Die Architektur¶
Das folgende Schaubild stellt eine konzeptionelle Sicht dar, wie der Datenverarbeitungsdienst in das größere OpenStack-Ökosystem passt.
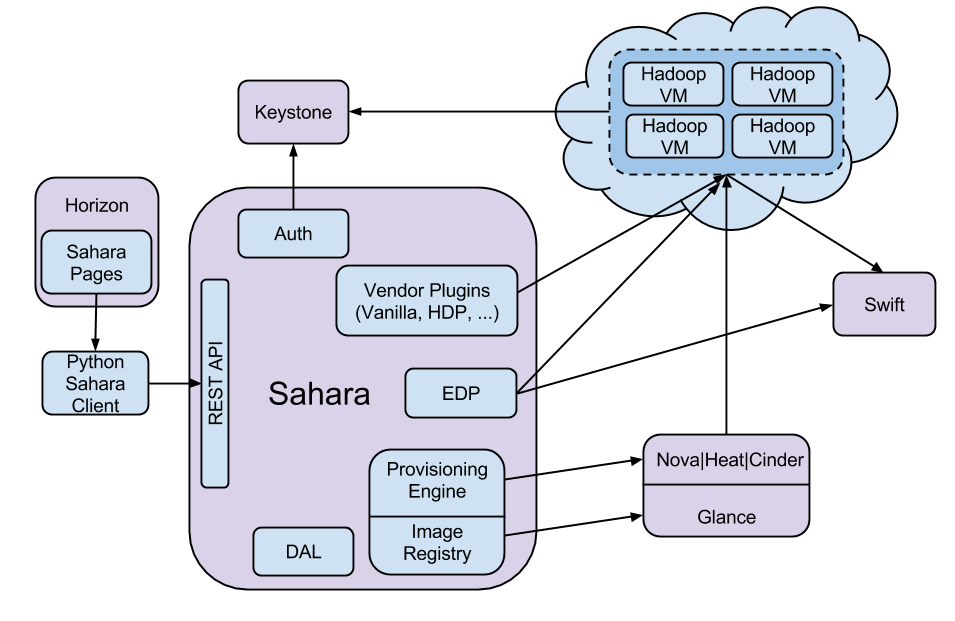
Der Datenverarbeitungsdienst nutzt die Compute-, Orchestrierungs-, Abbild- und Blockspeicherdienste während der Bereitstellung von Clustern stark. Es wird auch ein oder mehrere Netzwerke verwenden, die von dem Networking-Dienst erstellt wurden, der während der Cluster-Erstellung für den administrativen Zugriff auf die Instanzen bereitgestellt wird. Während Benutzer Framework-Anwendungen ausführen, greift der Controller und die Cluster auf den Object Storage Service zu. Angesichts dieser Service-Nutzung empfehlen wir Ihnen die folgenden Hinweise Systemdokumentation für die Katalogisierung aller Komponenten einer Anlage.
Beteiligte Technologien¶
Der Data Processing Service ist verantwortlich für die Bereitstellung und Verwaltung mehrerer Applikationen. Für ein vollständiges Verständnis der Sicherheitsoptionen empfehlen wir, dass die Betreiber eine allgemeine Vertrautheit mit diesen Anwendungen haben. Die Liste der hervorgehobenen Technologien ist in zwei Abschnitte unterteilt: Erstens, Anwendungen mit hoher Priorität, die einen größeren Einfluss auf die Sicherheit haben und zweitens unterstützende Anwendungen mit geringerem Einfluss.
Höhere Auswirkungen
Geringere Auswirkungen
Diese Technologien umfassen den Kern der Frameworks, die mit dem Data Processing Service eingesetzt werden. Zusätzlich zu diesen Technologien umfasst der Service auch gebündelte Frameworks, die von Drittanbietern zur Verfügung gestellt werden. Diese gebündelten Frameworks werden unter Verwendung der gleichen Kernstücke aufgebaut, die oben beschrieben wurden, sowie Konfigurationen und Anwendungen, die die Anbieter enthalten. Weitere Informationen zu den Drittanbieter-Rahmenbündeln finden Sie unter den folgenden Links:
Benutzerzugriff auf Ressourcen¶
Die Ressourcen (Cluster, Jobs und Datenquellen) des Datenverarbeitungsdienstes werden im Rahmen eines Projekts geteilt. Obwohl eine einzelne Controller-Installation mehrere Sätze von Ressourcen verwalten kann, werden diese Ressourcen jeweils zu einem einzigen Projekt skizziert. Angesichts dieser Einschränkung empfehlen wir, dass die Benutzer-Mitgliedschaft in Projekten genau überwacht wird, um eine ordnungsgemäße Trennung der Ressourcen zu gewährleisten.
Da die Sicherheitsanforderungen von Organisationen, die diesen Dienst einsetzen, auf der Grundlage ihrer spezifischen Bedürfnisse variieren, empfehlen wir, dass die Betreiber sich auf Datenschutz, Clusterverwaltung und Endbenutzeranwendungen als Ausgangspunkt für die Bewertung der Bedürfnisse ihrer Nutzer konzentrieren. Diese Entscheidungen werden dazu beitragen, den Prozess der Konfiguration des Benutzerzugriffs auf den Dienst zu führen. Für eine erweiterte Diskussion zum Datenschutz siehe: doc: ../ tenant-data.
Die Standardannahme für eine Datenverarbeitungsinstallation ist, dass Benutzer Zugriff auf alle Funktionalität in ihren Projekten haben. Für den Fall, dass eine umfangreichere Kontrolle erforderlich ist, stellt der Datenverarbeitungsdienst eine Richtliniendatei zur Verfügung (wie in ../identity/policy) beschrieben. Diese Konfigurationen werden in hohem Maße von den Bedürfnissen der Installationsorganisation abhängig sein, und als solche gibt es keinen allgemeinen Rat über ihre Verwendung: siehe:ref:data-processing-rbac-policies für Details.
