Datenbankzugriffskontrolle¶
Jeder der Kern-OpenStack-Dienste (Compute, Identity, Networking, Block Storage) speichert Status- und Konfigurationsinformationen in Datenbanken. In diesem Kapitel wird diskutiert, wie Datenbanken derzeit in OpenStack verwendet werden. Wir erforschen auch Sicherheitsbedenken und die Sicherheitsverzweigungen der Datenbank-Back-End-Auswahl.
OpenStack Datenbankzugriffsmodell¶
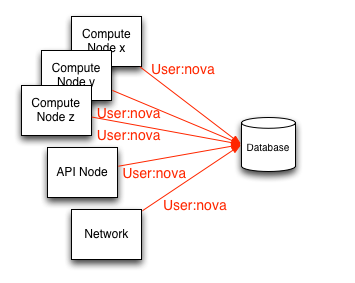
Alle Services innerhalb eines OpenStack-Projekts greifen auf eine einzige Datenbank zu. Es gibt derzeit keine Referenzrichtlinien zum Erstellen von Tabellen- oder Zeilenbasierten Zugriffsbeschränkungen für die Datenbank.
Es gibt keine allgemeinen Bestimmungen für die granulare Kontrolle der Datenbankoperationen in OpenStack. Zugriff und Privilegien werden einfach darauf gelegt, ob ein Knoten Zugriff auf die Datenbank hat oder nicht. In diesem Szenario können Knoten mit Zugriff auf die Datenbank über volle Berechtigungen für DROP-, INSERT- oder UPDATE-Funktionen verfügen.
Granulare Zutrittskontrolle¶
Standardmäßig greift jeder der OpenStack-Dienste und deren Prozesse auf die Datenbank zu, indem er einen gemeinsamen Satz von Anmeldeinformationen verwendet. Dies macht Audit-Datenbank-Operationen und widerruft Zugriffsberechtigungen von einem Dienst und seine Prozesse auf die Datenbank besonders schwierig.
Nova-conductor¶
Die Compute-Knoten sind die am wenigsten vertrauenswürdigen Dienste in OpenStack, weil sie Tenant-Instanzen hosten. Der ``nova-conductor``Service wurde eingeführt, um als Datenbank-Proxy zu dienen, der als Vermittler zwischen den Compute-Knoten und der Datenbank fungiert. Wir diskutieren es später in diesem Kapitel.
Wir empfehlen dringend:
Alle Datenbankkommunikationen werden in ein Management-Netzwerk integriert
Sicherung der Kommunikation mit TLS
Erstellen von eindeutigen Datenbankbenutzerkonten pro OpenStack-Dienstendpunkt (siehe unten)
Datenbank-Authentifizierung und Zugriffskontrolle¶
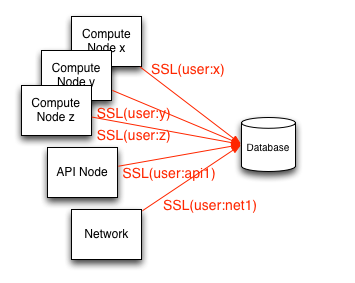
Angesichts der Risiken rund um den Zugriff auf die Datenbank, empfehlen wir dringend, dass einzelne Datenbank-Benutzerkonten pro Knoten erstellt werden, die Zugriff auf die Datenbank benötigen. Dies erleichtert eine bessere Analyse und Auditierung, um die Einhaltung zu gewährleisten, oder im Falle eines Kompromisses eines Knotens können Sie den kompromittierten Host isolieren, indem Sie den Zugriff für diesen Knoten auf die Datenbank bei der Erkennung entfernen. Bei der Erstellung dieser pro Service-Endpunkt-Datenbank-Benutzerkonten sollte darauf geachtet werden, dass sie so konfiguriert sind, dass sie TLS benötigen. Alternativ wird für erhöhte Sicherheit empfohlen, dass die Datenbankkonten zusätzlich zu Benutzernamen und Passwörtern unter Verwendung der X.509-Zertifikat-Authentifizierung konfiguriert werden.
Privilegien¶
Es sollte ein separates Datenbankadministrator (DBA) -Konto erstellt und geschützt werden, das über volle Berechtigungen zum Erstellen/Löschen von Datenbanken, zum Erstellen von Benutzerkonten und zum Aktualisieren von Benutzerberechtigungen verfügt. Dieses einfache Mittel der Trennung der Verantwortung hilft, versehentliche Fehlkonfiguration zu verhindern, senkt das Risiko und verringert den Kompromiss.
Die für die OpenStack-Dienste erstellten Datenbankbenutzerkonten und für jeden Knoten sollten Berechtigungen auf nur die Datenbank beschränkt sein, die für den Dienst relevant ist und auf dem der Knoten Mitglied ist.
Benötigte Benutzerkonten für SSL-Transport¶
Konfigurationsbeispiel #1: (MySQL)¶
GRANT ALL ON dbname.* to 'compute01'@'hostname' IDENTIFIED BY 'NOVA_DBPASS' REQUIRE SSL;
Konfigurationsbeispiel #2: (PostgreSQL)¶
In der Datei pg_hba.conf:
hostssl dbname compute01 hostname md5
Beachten Sie, dass dieser Befehl nur die Möglichkeit gibt, über SSL zu kommunizieren und nicht exklusiv ist. Andere Zugriffsmethoden, die einen unverschlüsselten Transport zulassen, sollten deaktiviert werden, so dass SSL die einzige Zugriffsmethode ist.
Der md5-Parameter definiert die Authentifizierungsmethode als Hash-
Passwort. Wir stellen ein sicheres Authentifizierungsbeispiel im folgenden
Abschnitt zur Verfügung.
OpenStack-Service-Datenbankkonfiguration¶
Wenn Ihr Datenbankserver für den TLS-Transport konfiguriert ist, müssen Sie die Zertifikatsautoritätsinformationen für die Verwendung mit der anfänglichen Verbindungszeichenfolge in der SQLAlchemy-Abfrage angeben.
Beispiel eines ``:sql_connection``string zu MySQL:¶
sql_connection = mysql://compute01:NOVA_DBPASS@localhost/nova?charset=utf8&ssl_ca=/etc/mysql/cacert.pem
Authentifizierung mit X.509 Zertifikaten¶
Die Sicherheit kann durch die Erstellung von X.509-Clientzertifikaten für die Authentifizierung erweitert werden. Die Authentifizierung auf die Datenbank auf diese Weise ermöglicht eine bessere Identitätssicherung des Clients, der die Verbindung zur Datenbank herstellt und sicherstellt, dass die Kommunikation verschlüsselt wird.
Konfigurationsbeispiel #1: (MySQL)¶
GRANT ALL on dbname.* to 'compute01'@'hostname' IDENTIFIED BY 'NOVA_DBPASS' REQUIRE SUBJECT
'/C=XX/ST=YYY/L=ZZZZ/O=cloudycloud/CN=compute01' AND ISSUER
'/C=XX/ST=YYY/L=ZZZZ/O=cloudycloud/CN=cloud-ca';
Konfigurationsbeispiel #2: (PostgreSQL)¶
hostssl dbname compute01 hostname cert
OpenStack-Service-Datenbankkonfiguration¶
Wenn Ihr Datenbankserver so konfiguriert ist, dass er X.509-Zertifikate für die Authentifizierung benötigt, müssen Sie die entsprechenden SQLAlchemy-Abfrageparameter für das Datenbankende festlegen. Diese Parameter geben den Zertifikat, den privaten Schlüssel und die Zertifikatsautoritätsinformationen für die Verwendung mit der anfänglichen Verbindungszeichenfolge an.
Beispiel für einen ``:sql_connection``String für X.509 Zertifikat- Authentifizierung für MySQL:
sql_connection = mysql://compute01:NOVA_DBPASS@localhost/nova?
charset=utf8&ssl_ca = /etc/mysql/cacert.pem&ssl_cert=/etc/mysql/server-cert.pem&ssl_key=/etc/mysql/server-key.pem
Nova-conductor¶
OpenStack Compute bietet einen Sub-Service namens nova-conductor an, der die Datenbankverbindungen projiziert, wobei der primäre Zweck darin besteht, dass die nova-Compute-Knoten mit dem nova-conductor verbunden sind, um die Datenpersistenz zu erfüllen, im Gegensatz zur direkten Kommunikation mit der Datenbank.
Nova-Conductor empfängt Anfragen über RPC und führt Aktionen im Auftrag des anrufenden Dienstes durch, ohne einen granularen Zugriff auf die Datenbank, ihre Tabellen oder Daten innerhalb zu gewähren. Nova-Conductor abstrahiert im Wesentlichen den direkten Datenbankzugriff von Compute-Knoten.
Diese Abstraktion bietet den Vorteil der Beschränkung von Diensten zur Ausführung von Methoden mit Parametern, ähnlich wie bei gespeicherten Prozeduren, wodurch verhindert wird, dass eine große Anzahl von Systemen direkt auf Daten zugreifen oder diese ändern kann. Dies geschieht, ohne dass diese Prozeduren im Kontext oder Umfang der Datenbank selbst gespeichert oder ausgeführt werden, eine häufige Kritik an typischen gespeicherten Prozeduren.
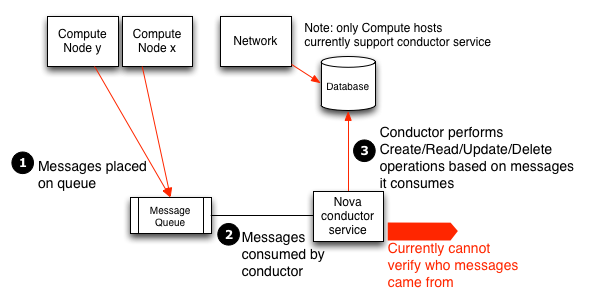
Leider kompliziert diese Lösung die Aufgabe der feinkörnigeren Zutrittskontrolle und die Möglichkeit, den Datenzugriff zu prüfen. Da der Nova-Conductor-Service Anfragen über RPC erhält, hebt er die Bedeutung der Verbesserung der Sicherheit von Messaging hervor. Jeder Knoten mit Zugriff auf die Nachrichtenwarteschlange kann diese vom Nova-Conductor bereitgestellten Methoden ausführen und die Datenbank effektiv modifizieren.
Beachten Sie, dass Nova-Conductor nur für OpenStack Compute gilt, direkter Datenbankzugriff von Compute-Hosts für den Betrieb anderer OpenStack-Komponenten wie Telemetrie (Ceilometer), Networking und Block Storage kann ausserdem noch erforderlich sein.
Um den nova-conductor zu deaktivieren, platzieren Sie folgendes in Ihre `` nova.conf``-Datei (auf Ihrem Compute-Hosts):
[conductor]
use_local = true
