Sicherheitsdienste für Instanzen¶
Entropie zu Instanzen¶
Wir betrachten Entropie, um auf die Qualität und Quelle der zufälligen Daten zu verweisen, die für eine Instanz verfügbar sind. Kryptographische Technologien beruhen typischerweise stark auf Zufälligkeit und erfordern einen qualitativ hochwertigen Entropiepool. Es ist in der Regel schwer für eine virtuelle Maschine, um genug Entropie zu erhalten, um diese Operationen zu unterstützen, die als Entropie-Hunger bezeichnet wird. Entropie-Hunger kann sich in Fällen als etwas scheinbar nicht verwandtes manifestieren. Zum Beispiel kann eine langsame Bootzeit durch die Instanz verursacht werden, die auf die ssh-Schlüsselgenerierung wartet. Entropie-Hunger kann auch dazu beitragen, dass Benutzer qualitativ schlechte Entropie-Quellen aus der Instanz verwenden, so dass Anwendungen in der Cloud insgesamt weniger sicher laufen.
Glücklicherweise kann ein Cloud-Architekt diese Probleme ansprechen, indem er eine qualitativ hochwertige Entropiequelle für die Cloud-Instanzen bereitstellt. Dies kann getan werden, indem genügend Hardware-Zufallszahlengeneratoren (HRNG) in der Cloud vorhanden sind, um die Instanzen zu unterstützen. In diesem Fall ist „genug“ etwas domänenspezifisch. Für den alltäglichen Betrieb wird eine moderne HRNG wahrscheinlich genug Entropie produzieren, um 50-100 Compute-Knoten zu unterstützen. HRNGs mit hoher Bandbreite, wie z. B. die RDRand-Anweisung, die mit Intel Ivy Bridge und neueren Prozessoren verfügbar ist, könnte möglicherweise mehr Knoten verarbeiten. Für eine gegebene Cloud muss ein Architekt die Anwendungsanforderungen verstehen, um sicherzustellen, dass eine ausreichende Entropie verfügbar ist.
Der Virtio RNG ist ein Zufallszahlengenerator, der standardmäßig ``/dev/ random``als Entropiequelle verwendet, kann jedoch so konfiguriert werden, dass er ein Hardware-RNG oder ein Tool wie den Entropie-Sammel-Daemon (EGD), um einen Weg zu schaffen, um die Entropie durch ein verteiltes System fair und sicher zu verteilen. Das Virtio RNG wird mit der ``hw_rng``Eigenschaft der Metadaten aktiviert, die zum Erstellen der Instanz verwendet wird.
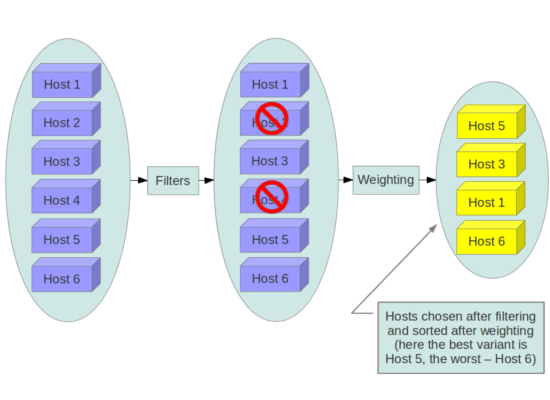
Planen von Instanzen auf Knoten¶
Bevor eine Instanz erstellt wird, muss ein Host für die Abbildinstanzierung
ausgewählt werden. Diese Auswahl erfolgt durch den Nova-Scheduler, der
bestimmt, wie man Rechen- und Volumenanforderungen abgibt.
The FilterScheduler is the default scheduler for OpenStack
Compute, although other schedulers exist (see the section Scheduling
in the OpenStack Configuration Reference
). This works in collaboration with ‚filter hints‘ to decide where an
instance should be started. This process of host selection allows
administrators to fulfill many different security and compliance
requirements. Depending on the cloud deployment type for example, one
could choose to have tenant instances reside on the same hosts whenever
possible if data isolation was a primary concern. Conversely one could
attempt to have instances for a tenant reside on as many different hosts
as possible for availability or fault tolerance reasons.
Filter-Scheduler fallen unter vier Hauptkategorien:
- Ressourcenbasierte Filter
Diese Filter erstellen eine Instanz basierend auf den Auslastungen der Hypervisor-Host-Sets und können auf freie oder gebrauchte Eigenschaften wie RAM, IO oder CPU-Auslastung auslösen.
- Abbildbasierte Filter
Dies delegiert die Instanzerstellung basierend auf dem verwendeten Abbild, wie z.B. dem Betriebssystem der VM oder dem verwendeten Abbildtyp.
- Umgebungsbasierte Filter
Dieser Filter erstellt eine Instanz, die auf externen Details basiert, z. B. in einem bestimmten IP-Bereich, über Verfügbarkeitszonen oder auf demselben Host wie eine andere Instanz.
- Benutzerdefinierte Kriterien
Dieser Filter delegiert die Instanzerstellung basierend auf Benutzer oder Administrator, sofern Kriterien wie Trusts oder Metadaten-Parsing bereitgestellt werden.
Es können mehrere Filter gleichzeitig angewendet werden, z.B. den `` ServerGroupAffinity``-Filter, um sicherzustellen, dass eine Instanz auf einem Mitglied eines bestimmten Satzes von Hosts und `` ServerGroupAntiAffinity``-Filter erstellt wird, um sicherzustellen, dass
Die ``GroupAffinity``und ``GroupAntiAffinity``Filter stehen im Konflikt und sollten nicht beide gleichzeitig aktiviert werden.
Der DiskFilter-Filter ist in der Lage, Speicherplatz zu
überzeichnen. Während es sich in der Regel nicht um ein Problem handelt,
kann dies ein Problem mit Speichergeräten sein, die dünn versorgt sind, und
dieser Filter sollte mit bewährten Quoten verwendet werden.
Wir empfehlen Ihnen, Filter zu deaktivieren, die Dinge, die von Benutzern bereitgestellt werden, analysieren oder manipuliert werden können, wie z.B. Metadaten.
Vertrauenswürdige Abbilder¶
In einer Cloud-Umgebung arbeiten die Benutzer entweder mit vorinstallierten Abbildern oder Abbildern, die sie selbst hochladen. In beiden Fällen sollten die Benutzer in der Lage sein, sicherzustellen, dass das Abbild, das sie nutzen, nicht manipuliert wurde. Die Fähigkeit, Abbilder zu verifizieren, ist ein wesentlicher Imperativ für die Sicherheit. Eine Kette von Vertrauen wird von der Quelle des Abbildes an das Ziel benötigt, wo es verwendet wird. Dies kann durch das Signieren von Abbildern, die aus vertrauenswürdigen Quellen erhalten wurden, und durch Verifizieren der Signatur vor der Verwendung erreicht werden. Verschiedene Wege zum Erhalten und Erstellen von verifizierten Abbildern werden nachfolgend beschrieben, gefolgt von einer Beschreibung der Abbildsignatur-Bestätigungsfunktion.
Abbilderstellungsprozess¶
Die OpenStack-Dokumentation enthält Anleitungen zum Erstellen und Hochladen eines Abbildes in den Abbilddienst. Darüber hinaus wird davon ausgegangen, dass Sie einen Prozess haben, mit dem Sie Betriebssysteme installieren und härten. So werden die folgenden Punkte zusätzliche Hinweise geben, wie Sie sicherstellen können, dass Ihre Abbilder sicher in OpenStack übertragen werden. Es gibt eine Vielzahl von Optionen für den Erhalt von Abbildern. Jeder hat spezifische Schritte, die helfen, die Provenienz des Abbildes zu validieren.
Die erste Möglichkeit besteht darin, Boot-Medien aus einer vertrauenswürdigen Quelle zu erhalten.
$ mkdir -p /tmp/download_directorycd /tmp/download_directory
$ wget http://mirror.anl.gov/pub/ubuntu-iso/CDs/precise/ubuntu-12.04.2-server-amd64.iso
$ wget http://mirror.anl.gov/pub/ubuntu-iso/CDs/precise/SHA256SUMS
$ wget http://mirror.anl.gov/pub/ubuntu-iso/CDs/precise/SHA256SUMS.gpg
$ gpg --keyserver hkp://keyserver.ubuntu.com --recv-keys 0xFBB75451
$ gpg --verify SHA256SUMS.gpg SHA256SUMSsha256sum -c SHA256SUMS 2>&1 | grep OK
Die zweite Option besteht darin, den OpenStack Virtual Machine Image Guide zu verwenden. In diesem Fall möchten Sie den OS Hardening Richtlinien Ihrer Organisation oder den von einem vertrauenswürdigen Drittanbieter wie die Linux STIGs zur Verfügung gestellt folgen.
Die endgültige Option ist, einen automatisierten Abbildbauer zu verwenden. Im folgenden Beispiel wird der Oz-Abbild-Builder verwendet. Die OpenStack-Community hat vor kurzem ein neueres Tool geschaffen, das es untersucht hat: disk-image-builder. Wir haben dieses Tool aus Sicht der Sicherheit nicht ausgewertet.
Beispiel für RHEL 6 CCE-26976-1, die dazu beitragen wird, NIST 800-53 Abschnitt AC-19(d) in Oz zu implementieren.
<template>
<name>centos64</name>
<os>
<name>RHEL-6</name>
<version>4</version>
<arch>x86_64</arch>
<install type='iso'>
<iso>http://trusted_local_iso_mirror/isos/x86_64/RHEL-6.4-x86_64-bin-DVD1.iso</iso>
</install>
<rootpw>CHANGE THIS TO YOUR ROOT PASSWORD</rootpw>
</os>
<description>RHEL 6.4 x86_64</description>
<repositories>
<repository name='epel-6'>
<url>http://download.fedoraproject.org/pub/epel/6/$basearch</url>
<signed>no</signed>
</repository>
</repositories>
<packages>
<package name='epel-release'/>
<package name='cloud-utils'/>
<package name='cloud-init'/>
</packages>
<commands>
<command name='update'>
yum update
yum clean all
rm -rf /var/log/yum
sed -i '/^HWADDR/d' /etc/sysconfig/network-scripts/ifcfg-eth0
echo -n > /etc/udev/rules.d/70-persistent-net.rules
echo -n > /lib/udev/rules.d/75-persistent-net-generator.rules
chkconfig --level 0123456 autofs off
service autofs stop
</command>
</commands>
</template>
It is recommended to avoid the manual image building process as it is complex and prone to error. Additionally, using an automated system like Oz for image building or a configuration management utility like Ansible or Puppet for post-boot image hardening gives you the ability to produce a consistent image as well as track compliance of your base image to its respective hardening guidelines over time.
Wenn Sie einen öffentlichen Cloud-Service abonnieren, sollten Sie mit dem Cloud-Anbieter nach einem Umriss des Prozesses, der verwendet wird, um ihre Standardbilder zu erstellen, prüfen. Wenn der Provider Ihnen erlaubt, Ihre eigenen Abbilder hochzuladen, müssen Sie sicherstellen, dass Sie in der Lage sind zu überprüfen, ob Ihr Abbild nicht geändert wurde, bevor Sie es verwenden, um eine Instanz zu erstellen. Weitere Informationen hierzu finden Sie im folgenden Abschnitt zur Abbildsignaturprüfung oder im folgenden Absatz, wenn Signaturen nicht verwendet werden können.
Abbilder kommen vom Image-Service zum Compute-Service auf einem Knoten. Diese Übertragung sollte durch den Betrieb über TLS geschützt werden. Sobald das Abbild auf dem Knoten ist, wird es mit einer grundlegenden Prüfsumme überprüft und dann wird seine Festplatte basierend auf der Größe der Instanz, die gestartet wird, erweitert. Wenn zu einem späteren Zeitpunkt das gleiche Abbild mit der gleichen Instanzgröße auf diesem Knoten gestartet wird, wird es aus dem gleichen erweiterten Abbild gestartet. Da dieses erweiterte Abbild vor dem Start nicht standardmäßig neu verifiziert wird, ist es möglich, dass es sich einer Manipulation unterzogen hat. Der Benutzer würde sich nicht bewusst sein, sich zu manipulieren, es sei denn, eine manuelle Inspektion der Dateien wird in dem resultierenden Abbild durchgeführt.
Abbildsignaturprüfung¶
Im OpenStack stehen nun mehrere Funktionen zur Abbildunterzeichnung zur Verfügung. Abgesehen von der Mitaka-Version kann der Image-Service diese signierten Abbilder verifizieren und, um eine vollständige Vertrauenskette zu liefern, hat der Compute-Dienst die Möglichkeit, die Abbildsignaturprüfung vor dem Abbild-Boot durchzuführen. Eine erfolgreiche Signaturvalidierung vor dem Abbildstart sorgt dafür, dass das signierte Abbild sich nicht geändert hat. Wenn diese Funktion aktiviert ist, kann eine nicht autorisierte Änderung von Abbildern (z. B. das Ändern des Abbildes auf Malware oder Rootkits) erkannt werden.
Administratoren können die Instanzsignaturprüfung aktivieren, indem sie in der /etc/nova/nova.conf-Datei das ``
verify_glance_signatures``-Flag auf True setzen. Wenn diese Option aktiviert ist, überprüft der Compute-Dienst automatisch die signierte Instanz, wenn sie aus dem Image-Dienst abgerufen wird. Wenn diese Überprüfung fehlschlägt, tritt der Boot nicht auf. Das OpenStack Operations Guide enthält Anleitungen zum Erstellen und Hochladen eines signierten Abbildes und zur Verwendung dieser Funktion. Weitere Informationen finden Sie unter Hinzufügen von Signierten Abbildern in der Betriebsanleitung.
Instanzmigrationen¶
OpenStack und die zugrunde liegenden Virtualisierungsschichten sorgen für die Live-Migration von Abbildern zwischen OpenStack-Knoten, so dass Sie problemlos Rolling Upgrades Ihrer OpenStack-Compute-Knoten ohne Ausfallzeiten durchführen können. Allerdings tragen auch Live-Migrationen ein erhebliches Risiko. Um die damit verbundenen Risiken zu verstehen, sind die High-Level-Schritte während einer Live-Migration:
Instanz auf Zielhost starten
Speicher übertragen
Stoppen der Gast- und Synchronisierungsdatenträger
Transferzustand
Starten des Gasts
Live-Migrationsrisiken¶
In verschiedenen Stadien des Live-Migrationsprozesses werden die Inhalte eines Instanzen Laufzeitspeichers und Festplatte über das Netzwerk im Klartext übertragen. So gibt es mehrere Risiken, die bei der Live-Migration angesprochen werden müssen. Die folgenden unvollständige Liste enthält einige dieser Risiken:
Denial of Service (DoS): Wenn während des Migrationsprozesses etwas fehlschlägt, könnte die Instanz verloren gehen.
Datenbelastung: Speicher- oder Datentransfers müssen sicher abgewickelt werden.
Datenmanipulation: Wenn Speicher- oder Datentransfers nicht sicher abgewickelt werden, könnte ein Angreifer Benutzerdaten während der Migration manipulieren.
Code-Injektion: Wenn Speicher- oder Datentransfers nicht sicher abgewickelt werden, könnte ein Angreifer während der Migration ausführbare Dateien entweder auf Festplatte oder im Speicher manipulieren.
Live-Migrationsminderungen¶
Es gibt mehrere Methoden, um einige der Risiken mit Live-Migrationen zu verringern, die folgenden Liste detailiert einige von diesen:
Live-Migration deaktivieren
Isoliertes Migrationsnetzwerk
Verschlüsselte Live-Migration
Live-Migration deaktivieren¶
Zu diesem Zeitpunkt ist die Live-Migration standardmäßig in OpenStack
aktiviert. Live-Migrationen können deaktiviert werden, indem Sie die
folgenden Zeilen zur Datei Nova policy.json hinzufügen:
{
"compute_extension:admin_actions:migrate": "!",
"compute_extension:admin_actions:migrateLive": "!",
}
Migrationsnetzwerk¶
Als allgemeine Praxis sollte der Live-Migrationsverkehr auf die Verwaltungssicherheitsdomäne beschränkt sein, siehe Sicherheitsgrenzen und Bedrohungen. Mit Live-Migrationsverkehr, aufgrund seiner Klartext-Natur und der Tatsache, dass Sie den Inhalt der Festplatte und Speicher einer laufenden Instanz übertragen, empfiehlt es sich, den Live-Migrationsverkehr weiter zu einem dedizierten Netzwerk zu trennen. Die Trennung des Verkehrs zu einem dedizierten Netzwerk kann das Risiko der Exposition verringern.
Verschlüsselte Live-Migration¶
Wenn es einen ausreichenden Business-Fall für die Live-Migration ermöglicht, dann kann libvirtd verschlüsselte Tunnel für die Live-Migrationen anbieten. Diese Funktion wird jedoch derzeit weder im OpenStack Dashboard noch in den nova-client-Befehlen angeboten und kann nur über die manuelle Konfiguration von libvirtd abgerufen werden. Der Live-Migrationsprozess wechselt dann zu den folgenden High-Level-Schritten:
Instanzdaten werden vom Hypervisor auf libvirtd kopiert.
Ein verschlüsselter Tunnel wird zwischen libvirtd Prozessen auf Quell- und Zielhosts erstellt.
Destination libvirtd host kopiert die Instanzen zurück zu einem zugrundeliegenden Hypervisor.
Überwachung, Alarmierung und Reporting¶
Als virtuelle Maschine von OpenStack ist ein Server-Abbild in der Lage, über Hosts repliziert zu werden, bewährte Praxis bei der Protokollierung gilt ähnlich zwischen physischen und virtuellen Hosts. Ereignisse auf Betriebssystemebene und auf Anwendungsebene sollten protokolliert werden, einschließlich Zugriffsereignisse für Hosts und Daten, Benutzerzugaben und Umzüge, Änderungen im Privileg und andere, wie sie von der Umgebung vorgegeben werden. Idealerweise können Sie diese Protokolle so konfigurieren, dass sie in einen Protokollaggregator exportieren, der Protokollereignisse sammelt, sie zur Analyse korreliert und sie als Referenz oder weitere Aktionen speichert. Ein gemeinsames Werkzeug, um dies zu tun ist ein ELK Stack, oder Elasticsearch, Logstash und Kibana.
Diese Protokolle sollten bei einer regelmäßigen Kadenz wie einer Live-Ansicht durch ein Network Operation Center (NOC) überprüft werden, oder wenn die Umgebung nicht groß genug ist, um einen NOC zu erfordern, dann sollten sich die Protokolle einem regelmäßigen Log-Review-Prozess unterziehen.
Viele interessante Ereignisse lösen einen Alarm aus, der an einen Responder geschickt wird. Häufig nimmt diese Warnung die Form einer E-Mail mit den Nachrichten von Interesse. Ein interessantes Ereignis könnte ein erhebliches Versagen sein, oder bekannte Gesundheits-Indikatoren eines ausstehenden Versagens. Zwei gemeinsame Dienstprogramme für die Verwaltung von Warnungen sind Nagios <https://www.nagios.org>``und `Zabbix.
Updates und Patches¶
Ein Hypervisor betreibt unabhängige virtuelle Maschinen. Dieser Hypervisor kann in einem Betriebssystem oder direkt auf der Hardware laufen (genannt Baremetal). Updates zum Hypervisor werden nicht auf die virtuellen Maschinen übertragen. Wenn zum Beispiel eine Bereitstellung XenServer verwendet und eine Reihe von virtuellen Maschinen hat, wird ein Update auf XenServer nichts aktualisieren, was auf den virtuellen Maschinen ausgeführt wird.
Daher empfiehlt es sich, eindeutige Besitz von virtuellen Maschinen zuzuordnen, und dass diese Eigentümer für das Hardening, den Einsatz und die fortlaufende Funktionalität der virtuellen Maschinen verantwortlich sind. Wir empfehlen auch, dass Updates regelmäßig bereitgestellt werden. Diese Patches sollten in einer Umgebung getestet werden, die der Produktion möglichst ähnlich ist, um sowohl die Stabilität als auch die Auflösung des Problems hinter dem Patch zu gewährleisten.
Firewalls und andere Host-basierte Sicherheitskontrollen¶
Die meisten gängigen Betriebssysteme umfassen Host-basierte Firewalls für zusätzliche Sicherheit. Während wir empfehlen, dass virtuelle Maschinen so viele Anwendungen wie möglich ausführen (sobald es Einzelfallinstanzen sind), sollten alle Anwendungen, die auf einer virtuellen Maschine laufen, profiliert werden, um festzustellen, auf welche Systemressourcen die Anwendung Zugriff haben muss, die niedrigste Ebene der Privilegien, damit sie läuft, und was der erwartete Netzwerkverkehr zu und von der virtuellen Maschine ist. Dieser erwartete Verkehr sollte der Host-basierten Firewall hinzugefügt werden, den den Verkehr erlaubt (oder Whitelist), zusammen mit jeder notwendigen Protokollierung und Management-Kommunikation wie SSH oder RDP. Jeder andere Verkehr sollte explizit in der Firewall-Konfiguration verweigert werden.
Auf Linux virtuellen Maschinen kann das oben beschriebene Anwendungsprofil in Verbindung mit einem Tool wie audit2all verwendet werden <http://wiki.centos.org/HowTos/SELinux#head-faa96b3fdd922004cdb988c1989e56191c257c01>`_, um eine SELinux-Policy aufzubauen, die sensible Systeminformationen auf den meisten Linux-Distributionen weiter schützt. SELinux nutzt eine Kombination von Benutzern, Richtlinien und Sicherheitskontexten, um die Ressourcen zu kompilieren, die für eine Anwendung erforderlich sind, um sie auszuführen und sie von anderen Systemressourcen zu segmentieren, die nicht benötigt werden.
OpenStack bietet Sicherheitsgruppen sowohl für Hosts als auch das Netzwerk, um die virtuellen Maschinen in einem bestimmten Projekt zusammen zu bringen. Diese ähneln Host-basierten Firewalls, da sie eingehenden Datenverkehr auf Port, Protokoll und Adresse zulassen oder verweigern, wobei jedoch Sicherheitsgruppenregeln nur auf eingehenden Datenverkehr angewendet werden, während Host-basierte Firewall-Regeln sowohl auf eingehende als auch auf angewendet werden können ausgehender Verkehr Es ist auch möglich, dass Host- und Netzwerksicherheitsgruppenregeln in Konflikt geraten und legitimer Verkehr verweigern. Wir empfehlen, sicherzustellen, dass Sicherheitsgruppen für die verwendete Vernetzung korrekt konfiguriert sind. Siehe Sicherheitsgruppen in diesem Leitfaden für mehr Details.
