Integritätslebenszyklus¶
Wir definieren den Integritätslebenszyklus als bewussten Prozess, der versichert, dass wir immer die erwartete Software mit den erwarteten Konfigurationen in der gesamten Cloud ausführen. Dieser Vorgang beginnt mit :term: sicheres Bootstrapping <secure boot> und wird durch Konfigurationsmanagement und Sicherheitsüberwachung beibehalten. In diesem Kapitel finden Sie Empfehlungen, wie Sie den Integritätslebenszyklus verfolgen können.
Sicheres Bootstrapping¶
Knoten in der Cloud - einschließlich Compute-, Storage-, Netzwerk-, Service- und Hybrid-Knoten - sollten einen automatisierten Provisioning-Prozess haben. Dadurch wird sichergestellt, dass die Knoten konsequent und korrekt bereitgestellt werden. Dies erleichtert auch das Sicherheitspatching, das Upgrade, die Fehlerbehebung und andere kritische Änderungen. Da dieser Prozess neue Software installiert, die auf den höchsten Berechtigungsstufen in der Cloud läuft, ist es wichtig zu überprüfen, ob die richtige Software installiert ist. Dazu gehören die frühesten Stufen des Bootvorgangs.
Es gibt eine Vielzahl von Technologien, die die Überprüfung dieser frühen Bootstufen ermöglichen. Diese benötigen typischerweise eine Hardwareunterstützung wie trusted platform module (TPM), die Intel Trusted Execution Technology (TXT), die dynamische Wurzel der Vertrauensmessung (DRTM) und das vereinfachte Extensible Firmware Interface (UEFI) In diesem Buch werden wir alle diese gemeinsam als sichere Boot-Technologien verweisen. Wir empfehlen, einen sicheren Boot zu verwenden, während wir anerkennen, dass viele der notwendigen Teile für die Bereitstellung von fortgeschrittenen technischen Fähigkeiten erforderlich sind, um die Werkzeuge für jede Umgebung anzupassen. Die Verwendung eines sicheren Boots erfordert eine tiefere Integration und Anpassung als viele der anderen Empfehlungen in diesem Leitfaden. TPM-Technologie, während in den letzten Jahren nur in Business-Class-Laptops und Desktops vorhanden, und wird nun in Servern zusammen mit unterstützenden BIOS eingesetzt. Eine ordnungsgemäße Planung ist für eine erfolgreiche sichere Boot-Bereitstellung unerlässlich.
Ein vollständiges Tutorial zur sicheren Boot-Bereitstellung geht über den Rahmen dieses Buches hinaus. Stattdessen bieten wir hier einen Rahmen für die Integration von sicheren Boot-Technologien mit dem typischen Knoten-Provisioning-Prozess. Für weitere Details verweisen wir Cloud-Architekten auf die zugehörigen Spezifikationen und Software-Konfigurationshandbücher.
Knoten-Provisionierung¶
Knoten sollten Preboot eXecution Environment (PXE) für die Bereitstellung verwenden. Dies verringert den Aufwand für die Wiederherstellung von Knoten erheblich. Der typische Prozess beinhaltet, dass der Knoten verschiedene Bootstufen empfängt - das ist schrittweise komplexere Software, um von einem Server auszuführen.
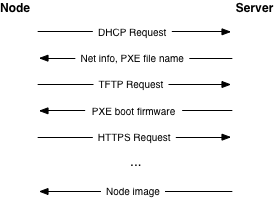
We recommend using a separate, isolated network within the management security domain for provisioning. This network will handle all PXE traffic, along with the subsequent boot stage downloads depicted above. Note that the node boot process begins with two insecure operations: DHCP and TFTP. Then the boot process uses TLS to download the remaining information required to deploy the node. This may be an operating system installer, a basic install managed by Ansible or Puppet, or even a complete file system image that is written directly to disk.
Die Nutzung von TLS während der PXE-Boot-Prozess ist etwas schwieriger, gemeinsame PXE-Firmware-Projekte, wie iPXE, bieten diese Unterstützung. In der Regel handelt es sich dabei um den Aufbau der PXE-Firmware mit Kenntnis der zulässigen TLS-Zertifikatskette, so dass sie das Serverzertifikat ordnungsgemäß validieren kann. Dies hält die Stange für einen Angreifer höher, indem sie die Anzahl der unsicheren, einfachen Textnetzwerke begrenzt.
Verifizierter Boot¶
Im Allgemeinen gibt es zwei verschiedene Strategien für die Überprüfung des Boot-Prozesses. Traditionelles sicheres Booten validiert den Code, der bei jedem Schritt des Prozesses ausgeführt wird, und stoppt den Boot, wenn Code falsch ist. Boot-Bescheinigung wird aufzeichnen, welcher Code bei jedem Schritt ausgeführt wird, und diese Informationen an eine andere Maschine als Beweis liefern, dass der Boot-Prozess wie erwartet abgeschlossen ist. In beiden Fällen ist der erste Schritt, um jedes Stück Code zu messen, bevor es ausgeführt wird. In diesem Zusammenhang ist eine Messung effektiv ein SHA-1-Hash des Codes, der vor der Ausführung durchgeführt wird. Der Hash wird in einem Plattform-Konfigurationsregister (PCR) im TPM gespeichert.
Bemerkung
SHA-1 wird hier verwendet, denn das ist es, was die TPM-Chips unterstützen.
Jedes TPM hat mindestens 24 PCRs. Die TCG Generic Server Specification, v1.0, März 2005, definiert die PCR-Zuweisungen für Boot-Time Integrity Messungen. Die folgende Tabelle zeigt eine typische PCR-Konfiguration. Der Kontext gibt an, ob die Werte auf der Basis der Knotenhardware (Firmware) oder der auf dem Knoten bereitgestellten Software ermittelt werden. Einige Werte werden durch Firmware-Versionen, Plattengrößen und andere Low-Level-Informationen beeinflusst. Daher ist es wichtig, über das Konfigurationsmanagement gute Praktiken zu haben, um sicherzustellen, dass jedes verwendete System genau wie gewünscht konfiguriert ist.
Neu registrieren |
Was wird gemessen |
Kontext |
|---|---|---|
PCR-00 |
Core Root of Trust Measurement (CRTM), BIOS-Code, Host-Plattform-Erweiterungen |
Hardware |
PCR-01 |
Host-Plattform-Konfiguration |
Hardware |
PCR-02 |
Option ROM-Code |
Hardware |
PCR-03 |
Option ROM-Konfiguration und Daten |
Hardware |
PCR-04 |
Initial Program Loader (IPL) Code. Zum Beispiel Master-Boot-Record. |
Software |
PCR-05 |
IPL-Code-Konfiguration und Daten |
Software |
PCR-06 |
Zustandsübergang und Weckereignisse |
Software |
PCR-07 |
Host-Plattform-Hersteller-Steuerung |
Software |
PCR-08 |
Plattformspezifische, oft Kernel-, Kernel-Erweiterungen und Treiber |
Software |
PCR-09 |
Plattformspezifisch, oft Initramfs |
Software |
PCR-10 bis PCR-23 |
Plattformspezifisch |
Software |
Secure boot may be an option for building your cloud, but requires careful planning in terms of hardware selection. For example, ensure that you have a TPM and Intel TXT support. Then verify how the node hardware vendor populates the PCR values. For example, which values will be available for validation. Typically the PCR values listed under the software context in the table above are the ones that a cloud architect has direct control over. But even these may change as the software in the cloud is upgraded. Configuration management should be linked into the PCR policy engine to ensure that the validation is always up to date.
Jeder Hersteller muss das BIOS- und Firmware-Code für seine Server bereitstellen. Verschiedene Server, Hypervisor und Betriebssysteme sind wählbar, um verschiedene PCRs zu besetzen. In den meisten Einsätzen in derrealen Welt ist es unmöglich, jede PCR gegen eine bekannte gute Menge („goldene Messung“) zu validieren. Die Erfahrung hat gezeigt, dass der Messprozess für eine gegebene PCR auch innerhalb der Produktlinie eines einzelnen Herstellers nicht konsistent sein kann. Wir empfehlen, eine Baseline für jeden Server zu erstellen und die PCR-Werte für unerwartete Änderungen zu überwachen. Drittanbieter-Software steht zur Verfügung, um den TPM-Bereitstellungs- und Überwachungsprozess zu unterstützen, abhängig von Ihrer gewählten Hypervisor-Lösung.
Der erste Programm-Loader (IPL)-Code wird höchstwahrscheinlich die PXE-Firmware sein, vorausgesetzt, dass die Knoten-Implementierungsstrategie oben skizziert ist. Daher kann der sichere Boot- oder Boot-Bescheinigungsprozess alle frühen Start-Boot-Code wie BIOS, Firmware, die PXE-Firmware und das Kernel-Image messen. Sicherstellen, dass jeder Knoten die richtigen Versionen dieser Stücke installiert hat, bietet eine solide Grundlage, auf der der Rest des Knoten-Software-Stacks zu bauen ist.
Abhängig von der gewählten Strategie wird im Falle eines Fehlers der Knoten entweder nicht gestartet oder er kann den Fehler an eine andere Entität in der Cloud melden. Für einen sicheren Start wird der Knoten nicht booten und ein Bereitstellungsdienst innerhalb der Verwaltungssicherheitsdomäne muss dies erkennen und das Ereignis protokollieren. Für die Boot-Bescheinigung wird der Knoten bereits ausgeführt, wenn der Fehler erkannt wird. In diesem Fall sollte der Knoten sofort durch die Deaktivierung seines Netzwerkzugriffs unter Quarantäne gestellt werden. Dann sollte das Ereignis für die Grundursache analysiert werden. In beiden Fällen sollte die Richtlinie diktieren, wie man nach einem Ausfall vorgehen soll. Eine Cloud kann automatisch versuchen, einen Knoten eine bestimmte Anzahl von Malen wiederzugeben. Oder es kann sofort einen Cloud-Administrator benachrichtigen, um das Problem zu untersuchen. Die richtige Richtlinie hier ist die Bereitstellung und Fehler Modus spezifisch.
Knotenhärtung¶
An diesem Punkt wissen wir, dass der Knoten mit dem richtigen Kernel und zugrunde liegenden Komponenten gebootet hat. Der nächste Schritt ist, das Betriebssystem zu härten und es beginnt mit einer Reihe von Industrie-akzeptierten Härtungskontrollen. Die folgenden Guides sind gute Beispiele:
- „Sicherheitstechnische Einführungsleitfaden (STIG) <http://iase.disa.mil/stigs/Pages/index.aspx>`_
Die Verteidigungsinformationssystem-Agentur (DISA) (Teil des Verteidigungsministeriums der USA) veröffentlicht STIG-Inhalte für verschiedene Betriebssysteme, Anwendungen und Hardware. Die Kontrollen werden ohne Lizenz veröffentlicht.
- Center for Internet Security (CIS) Benchmarks
CIS veröffentlicht regelmäßig Sicherheits-Benchmarks sowie automatisierte Tools, die diese Sicherheitskontrollen automatisch anwenden. Diese Benchmarks werden unter einer Creative Commons Lizenz veröffentlicht das hat einige einschränkungen
Diese Sicherheitskontrollen werden am besten über automatisierte Methoden angewendet. Die Automatisierung sorgt dafür, dass die Bedienelemente für jedes System jeweils gleich angewendet werden und sie bieten auch eine schnelle Methode zur Auditierung eines bestehenden Systems. Es gibt mehrere Möglichkeiten der Automatisierung:
- OpenSCAP
OpenSCAP ist ein Open-Source-Tool, das SCAP-Inhalte (XML-Dateien, die Sicherheitskontrollen beschreiben) und wendet diesen Inhalt auf verschiedene Systeme an. Die meisten verfügbaren Inhalte sind heute für Red Hat Enterprise Linux und CentOS verfügbar, aber die Werkzeuge arbeiten auf jedem Linux- oder Windows-System.
- ansible-hardening
Das ansible-hardening Projekt bietet eine Ansible Rolle, die Sicherheitskontrollen auf eine breite Palette von Linux-Betriebssystemen anwendet. Es kann auch verwendet werden, um ein bestehendes System zu prüfen. Jede Kontrolle wird sorgfältig überprüft, um festzustellen, ob sie ein Produktionssystem beschädigen könnte. Die Bedienelemente basieren auf dem Red Hat Enterprise Linux 7 STIG.
Eine vollständige Härtung eines Systems ist ein anspruchsvoller Prozess und es kann eine beträchtliche Menge an Änderungen an einigen Systemen erfordern. Einige dieser Änderungen könnten die Produktionsbelastung beeinträchtigen. Wenn ein System nicht vollständig gehärtet werden kann, sind die folgenden zwei Änderungen dringend empfohlen, um die Sicherheit ohne große Störungen zu erhöhen:
- Obligatorische Zugriffskontrolle (MAC)
Obligatorische Zugriffskontrollen beeinflussen alle Benutzer auf dem System, einschließlich Root, und es ist die Aufgabe des Kernels, die Aktivität gegen die aktuelle Sicherheitsrichtlinie zu überprüfen. Wenn die Aktivität nicht innerhalb der erlaubten Richtlinie liegt, wird sie auch für den Root-Benutzer gesperrt. Überprüfen Sie die Diskussion über sVirt, SELinux und AppArmor unten für weitere Details.
- Pakete entfernen und Dienste aufheben
Stellen Sie sicher, dass das System die wenigsten installierten Pakete installiert und die Dienste wie möglich ausgeführt haben. Das Entfernen nicht benötigter Pakete erleichtert das Patching und reduziert die Anzahl der Elemente auf dem System, die zu einem Bruch führen könnten. Das Stoppen von unnötigen Diensten schrumpft die Angriffsfläche auf dem System und macht es schwieriger, anzugreifen.
Wir empfehlen auch folgende zusätzliche Schritte für Produktionsknoten:
- Nur-Lese-Dateisystem
Verwenden Sie ggf. ein schreibgeschütztes Dateisystem. Stellen Sie sicher, dass beschreibbare Dateisysteme keine Ausführung zulassen. Dies kann mit dem
- Systemvalidierung
Schließlich sollte der Knotenkernel einen Mechanismus haben, um zu bestätigen, dass der Rest des Knotens in einem bekannten guten Zustand beginnt. Dies stellt die notwendige Verbindung vom Boot-Validierungsprozess zur Validierung des gesamten Systems zur Verfügung. Die Schritte dafür sind Einsatzspezifisch. Als Beispiel könnte ein Kernel-Modul einen Hash über die Blöcke, die das Dateisystem enthalten, verifizieren, bevor es mit dm-verity installiert wird <https://gitlab.com/cryptsetup/cryptsetup/wikis/DMVerity>`__.
Runtime Verifizierung¶
Sobald der Knoten läuft, müssen wir sicherstellen, dass es in einem guten Zustand im Laufe der Zeit bleibt. Im Großen und Ganzen beinhaltet dies sowohl das Konfigurationsmanagement als auch die Sicherheitsüberwachung. Die Ziele für jeden dieser Bereiche sind unterschiedlich. Durch die Kontrolle von beiden erreichen wir eine höhere Sicherheit, dass das System wie gewünscht arbeitet. Wir besprechen das Konfigurationsmanagement im Managementbereich und die Sicherheitsüberwachung unten.
Intrusion Detection System¶
Host-basierte Intrusion Detection Tools sind auch nützlich für die automatisierte Validierung der Cloud Internals. Es gibt eine Vielzahl von Host-basierten Intrusion Detection Tools zur Verfügung. Einige sind Open-Source-Projekte, die frei verfügbar sind, während andere kommerziell sind. Typischerweise analysieren diese Werkzeuge Daten aus einer Vielzahl von Quellen und erzeugen Sicherheitsalarme basierend auf Regelsätzen und/oder Schulungen. Typische Fähigkeiten umfassen Log-Analyse, Dateiintegritätsprüfung, Richtlinienüberwachung und Rootkit-Erkennung. Fortgeschrittene - oft benutzerdefinierte Werkzeuge können bestätigen, dass In-Memory-Prozessbilder mit der ausführbaren Datei übereinstimmen und den Ausführungszustand eines laufenden Prozesses validieren.
Eine kritische politische Entscheidung für einen Cloud-Architekten ist, was mit der Ausgabe eines Sicherheits-Monitoring-Tools zu tun ist. Es gibt effektiv zwei Möglichkeiten. Die erste ist, um einen Menschen zu untersuchen und/oder Korrekturmaßnahmen zu warnen. Dies könnte durch Einbeziehen der Sicherheitsalarm in einem Protokoll oder Ereignis-Feed für Cloud-Administratoren erfolgen. Die zweite Option ist, dass die Cloud irgendeine Form von Abhilfemaßnahmen automatisch haben wird, zusätzlich zur Protokollierung der Veranstaltung. Abhilfemaßnahmen könnten alles von der Neuinstallation eines Knotens zur Ausführung einer kleineren Dienstkonfiguration enthalten. Automatische Abhilfemaßnahmen können jedoch aufgrund der Möglichkeit von falschen Positiven herausfordernd sein.
Falsche Positive treten auf, wenn das Sicherheitsüberwachungsgerät einen Sicherheitsalarm für ein gutartiges Ereignis erzeugt. Aufgrund der Natur der Sicherheitsüberwachungsinstrumente werden von Zeit zu Zeit sicherlich falsche Positives auftreten. Typischerweise kann ein Cloud-Administrator Sicherheits-Monitoring-Tools, um die falschen Positiven zu reduzieren, aber dies kann auch die gesamte Erkennungsrate gleichzeitig reduzieren. Diese klassischen Kompromisse müssen bei der Einrichtung eines Sicherheitsüberwachungssystems in der Cloud verstanden und berücksichtigt werden.
Die Auswahl und Konfiguration eines Host-basierten Intrusion Detection-Tools ist hochgradig implementierungsspezifisch. Wir empfehlen Ihnen, die folgenden Open-Source-Projekte zu erkunden, die eine Vielzahl von Host-basierten Intrusion Detection- und File Monitoring-Funktionen implementieren.
Netzwerk-Intrusion Detection Tools ergänzen die Host-basierten Tools. OpenStack verfügt nicht über ein bestimmtes Netzwerk IDS integriert, aber OpenStack Networking bietet einen Plug-In-Mechanismus, um verschiedene Technologien über die Networking API zu aktivieren. Diese Plug-in-Architektur ermöglicht es den Tenants, API-Erweiterungen zu entwickeln, um ihre eigenen fortschrittlichen Netzwerkdienste wie eine Firewall, ein Intrusion Detection System oder ein VPN zwischen den VMs einzufügen und zu konfigurieren.
Ähnlich wie bei Host-basierten Tools ist die Auswahl und Konfiguration eines netzwerkbasierten Intrusion Detection-Tools implementierungsspezifisch. Snort ist das führende Open-Source-Netzwerk-Intrusion Detection Tool und ein guter Ausgangspunkt, um mehr zu lernen.
Es gibt einige wichtige Sicherheitsüberlegungen für Netzwerk- und Host-basierte Intrusion Detection Systeme.
Es ist wichtig, die Platzierung der Netzwerk-IDS auf der Cloud zu betrachten (z. B. Hinzufügen zur Netzwerkgrenze und/oder um sensible Netzwerke). Die Platzierung hängt von Ihrer Netzwerkumgebung ab, aber stellen Sie sicher, dass Sie die Auswirkungen der IDS auf Ihre Dienste überwachen können, je nachdem, wo Sie es hinzufügen möchten. Verschlüsselter Verkehr, wie TLS, kann im Allgemeinen nicht von einem Netzwerk-IDS auf Inhalte geprüft werden. Allerdings kann die Netzwerk-IDS noch einige Vorteile bei der Identifizierung von anomalen unverschlüsselten Verkehr auf dem Netzwerk.
In einigen Bereitstellungen kann es erforderlich sein, Host-basierte IDS auf sensible Komponenten auf Sicherheitsbereichsbrücken hinzuzufügen. Eine Host-basierte IDS kann anomale Aktivität durch kompromittierte oder nicht autorisierte Prozesse auf der Komponente erkennen. Das IDS sollte Warn- und Protokollinformationen über das Management-Netzwerk übertragen.
Serverhärtung¶
Server in der Cloud, einschließlich undercloud und overcloud Infrastruktur, sollten Hardening Best Practices implementieren. Da die Betriebssystem- und Serverhärtung üblich ist, gelten die bewährten Vorgehensweisen, einschließlich, aber nicht beschränkt auf die Protokollierung, Benutzerkontenbeschränkungen und regelmäßige Aktualisierungen werden hier nicht behandelt, sondern sollten auf alle Infrastrukturen angewendet werden.
Dateiintegritätsmanagement (FIM)¶
File Integrity Management (FIM) ist die Methode, um sicherzustellen, dass Dateien wie sensible System- oder Anwendungskonfigurationsdateien nicht beschädigt oder geändert werden, um unbefugten Zugriff oder böswilliges Verhalten zu ermöglichen. Dies kann durch ein Dienstprogramm wie Samhain, die eine Prüfsumme Hash der angegebenen Ressource zu erstellen und dann validieren, dass Hash in regelmäßigen Abständen oder durch ein Werkzeug wie DMVerity, das einen Hash von Block-Geräte nehmen kann und diese Hashes validiert werden, wenn sie vom System angesprochen werden, bevor sie dem Benutzer präsentiert werden.
These should be put in place to monitor and report on changes to system,
hypervisor, and application configuration files such as
/etc/pam.d/system-auth and /etc/keystone/keystone.conf,
as well as kernel modules (such as virtio). Best practice is to use
the lsmod command to show what is regularly being loaded on a
system to help determine what should or should not be included in FIM checks.
