Integritas siklus hidup¶
Kami mendefinisikan siklus hidup integritas sebagai proses yang disengaja yang memberikan kepastian bahwa kami selalu menjalankan perangkat lunak yang diharapkan dengan konfigurasi yang diharapkan di seluruh awan. Proses ini dimulai dengan secure bootstrapping dan dikelola melalui manajemen konfigurasi dan pemantauan keamanan. Bab ini memberikan rekomendasi bagaimana mendekati proses siklus hidup integritas.
Amankan bootstrapping¶
Node di awan -termasuk komputasi, penyimpanan, jaringan, layanan, dan node hibrida- harus memiliki proses penyediaan otomatis. Hal ini memastikan bahwa node ditetapkan secara konsisten dan benar. Ini juga memfasilitasi keamanan patch, upgrade, perbaikan bug, dan perubahan penting lainnya. Karena proses ini menginstal perangkat lunak baru yang berjalan pada tingkat hak istimewa tertinggi di awan, penting untuk memastikan perangkat lunak yang benar diinstal. Ini termasuk tahap awal proses boot.
Ada berbagai teknologi yang memungkinkan verifikasi tahap boot awal ini. Ini biasanya memerlukan dukungan perangkat keras sepert trusted platform module (TPM), Intel Trusted Execution Technology (TXT), dynamic root of trust measurement (DRTM), dan booting aman Unified Extensible Firmware Interface (UEFI). Dalam buku ini, kita akan mengacu pada semua ini secara kolektif sebagai teknologi secure boot. Sebaiknya gunakan boot aman, sambil mengakui bahwa banyak dari potongan yang diperlukan untuk menerapkan ini memerlukan ketrampilan teknis lanjutan untuk menyesuaikan alat untuk setiap lingkungan. Memanfaatkan boot yang aman akan memerlukan integrasi dan penyesuaian yang lebih dalam daripada banyak rekomendasi lainnya dalam panduan ini. Teknologi TPM, meski umum ada di kebanyakan laptop kelas bisnis dan desktop selama beberapa tahun, dan kini mulai tersedia di server bersamaan dengan BIOS pendukung. Perencanaan yang tepat sangat penting untuk penerapan booting aman yang berhasil.
Tutorial lengkap tentang penerapan booting aman berada di luar cakupan buku ini. Sebagai gantinya, di sini kami menyediakan kerangka kerja bagaimana mengintegrasikan teknologi boot aman dengan proses penyediaan node tipikal. Untuk rincian tambahan, arsitek awan harus mengacu pada spesifikasi dan manual konfigurasi perangkat lunak yang terkait.
Penyediaan Node¶
Node harus menggunakan Preboot eXecution Environment (PXE) untuk penyediaan. Hal ini secara signifikan mengurangi upaya yang diperlukan untuk memindahkan node. Proses yang khas melibatkan node yang menerima berbagai tahap boot -yaitu perangkat lunak yang semakin kompleks untuk dijalankan- dari server.
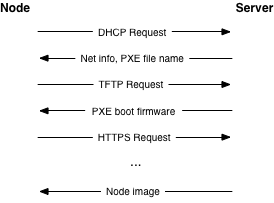
We recommend using a separate, isolated network within the management security domain for provisioning. This network will handle all PXE traffic, along with the subsequent boot stage downloads depicted above. Note that the node boot process begins with two insecure operations: DHCP and TFTP. Then the boot process uses TLS to download the remaining information required to deploy the node. This may be an operating system installer, a basic install managed by Ansible or Puppet, or even a complete file system image that is written directly to disk.
Saat menggunakan TLS selama proses boot PXE agak lebih menantang, proyek firmware PXE yang umum, seperti iPXE, memberikan dukungan ini. Biasanya ini melibatkan pembuatan firmware PXE dengan pengetahuan tentang rantai sertifikat TLS yang diizinkan sehingga dapat memvalidasi sertifikat server dengan benar. Ini memunculkan halangan untuk penyerang dengan membatasi jumlah operasi jaringan teks biasa yang tidak aman.
Boot terverifikasi¶
Secara umum, ada dua strategi yang berbeda untuk memverifikasi proses booting. secure boot akan memvalidasi kode yang dijalankan pada setiap langkah dalam proses, dan menghentikan boot jika kode salah. *Boot attestation * akan mencatat kode mana yang dijalankan pada setiap langkah, dan berikan informasi ini ke mesin lain sebagai bukti bahwa proses boot selesai seperti yang diharapkan. Dalam kedua kasus tersebut, langkah pertama adalah mengukur setiap potongan kode sebelum dijalankan. Dalam konteks ini, pengukuran secara efektif merupakan hash kode SHA-1, yang diambil sebelum dijalankan. Hash disimpan dalam platform configuration register (PCR) di TPM.
Catatan
SHA-1 digunakan disini karena ini adalah apa yang didukung oleh chip TPM.
Setiap TPM memiliki setidaknya 24 PCR. Spesifikasi Server Generik TCG, v1.0, Maret 2005, mendefinisikan tugas PCR untuk pengukuran integritas waktu booting. Tabel di bawah menunjukkan konfigurasi PCR yang khas. Konteksnya menunjukkan jika nilai ditentukan berdasarkan perangkat keras node (firmware) atau perangkat lunak yang ada pada node. Beberapa nilai dipengaruhi oleh versi firmware, ukuran disk, dan informasi tingkat rendah lainnya. Oleh karena itu, penting untuk memiliki praktik yang baik di tempat seputar pengelolaan konfigurasi untuk memastikan bahwa setiap sistem yang digunakan dikonfigurasi sesuai keinginan.
Register |
What is measured |
Context |
|---|---|---|
PCR-00 |
Core Root of Trust Measurement (CRTM), BIOS code, Host platform extensions |
Hardware |
PCR-01 |
Konfigurasi platform host |
Hardware |
PCR-02 |
Opsi kode ROM |
Hardware |
PCR-03 |
Pilihan konfigurasi dan data ROM |
Hardware |
PCR-04 |
Kode Initial Program Loader (IPL). Contohnya, master boot record. |
Software |
PCR-05 |
Konfigurasi dan data kode IPL |
Software |
PCR-06 |
State transition dan wake events |
Software |
PCR-07 |
Kontrol pabrikan platform host |
Software |
PCR-08 |
Platform specific, often kernel, kernel extensions, dan drivers |
Software |
PCR-09 |
Platform specific, often Initramfs |
Software |
PCR-10 to PCR-23 |
Platform specific |
Software |
Secure boot mungkin merupakan opsi untuk membangun cloud Anda, tetapi membutuhkan perencanaan yang cermat dalam hal pemilihan perangkat keras. Misalnya, pastikan Anda memiliki dukungan TPM dan Intel TXT. Kemudian verifikasi bagaimana vendor perangkat keras node mengisi nilai-nilai PCR. Misalnya, nilai mana yang akan tersedia untuk validasi. Biasanya nilai PCR yang terdaftar di bawah konteks perangkat lunak dalam tabel di atas adalah nilai-nilai yang dimiliki oleh arsitek cloud. Tetapi bahkan ini dapat berubah ketika perangkat lunak di cloud ditingkatkan. Manajemen konfigurasi harus ditautkan ke mesin kebijakan PCR untuk memastikan bahwa validasi selalu terkini.
Setiap pabrikan harus menyediakan kode BIOS dan firmware untuk server mereka. Server yang berbeda, hypervisor, dan sistem operasi akan memilih untuk mengisi PCR yang berbeda. Dalam kebanyakan penyebaran dunia nyata, tidak mungkin memvalidasi setiap PCR terhadap kuantitas yang diketahui ("golden measurement"). Pengalaman menunjukkan bahwa, bahkan dalam lini produk vendor tunggal, proses pengukuran untuk PCR tertentu mungkin tidak konsisten. Sebaiknya buat baseline untuk setiap server dan pantau nilai PCR untuk perubahan yang tidak diharapkan. Perangkat lunak pihak ketiga mungkin tersedia untuk membantu proses pengadaan dan pemantauan TPM, tergantung pada solusi hypervisor yang Anda pilih.
Kode initial program loader (IPL) kemungkinan besar adalah firmware PXE, dengan asumsi strategi penyebaran node yang diuraikan di atas. Oleh karena itu, proses pengesahan booting atau booting yang aman dapat mengukur semua kode boot tahap awal, seperti BIOS, firmware, firmware PXE, dan kernel image. Memastikan bahwa setiap node memiliki versi yang benar dari potongan-potongan ini yang terpasang memberikan fondasi yang kokoh untuk membangun tumpukan perangkat lunak node lainnya.
Bergantung pada strategi yang dipilih, jika terjadi kegagalan, node akan gagal booting atau dapat melaporkan kegagalan kembali ke entitas lain di awan. Untuk boot aman, node terjadi gagal booting dan kemudian layanan provisioning dalam domain keamanan manajemen harus mengenali ini dan mencatat kejadian. Untuk pengesahan booting, node sudah akan berjalan saat failure terdeteksi. Dalam hal ini node harus segera dikarantina dengan menonaktifkan akses jaringannya. Maka event tersebut harus dianalisis untuk akar permasalahannya. Dalam kasus tersebut, kebijakan harus mendikte bagaimana melanjutkan setelah kegagalan. Awan secara otomatis dapat mencoba menyediakan kembali node beberapa kali. Atau mungkin segera memberitahu administrator awan untuk menyelidiki masalahnya. Kebijakan yang tepat disini akan bersifat deployment dan failure mode yang spesifik.
Pengerasan node¶
Pada titik ini kita tahu bahwa node telah boot dengan kernel yang benar dan komponen yang mendasarinya. Langkah selanjutnya adalah mengeraskan sistem operasi dan dimulai dengan seperangkat kontrol pengerasan yang diterima industri. Panduan berikut adalah contoh yang baik:
- Security Technical Implementation Guide (STIG)
The Defense Information Systems Agency (DISA) (bagian dari United States Department of Defense) menerbitkan konten STIG untuk berbagai sistem operasi, aplikasi, dan perangkat keras. Kontrol diterbitkan tanpa lisensi apapun.
- Center for Internet Security (CIS) Benchmarks
CIS secara teratur menerbitkan tolok ukur keamanan serta alat otomatis yang menerapkan kontrol keamanan secara otomatis. Tolok ukur ini dipublikasikan di bawah Creative Commons license yang memiliki beberapa keterbatasan.
Kontrol keamanan ini paling baik diterapkan melalui metode otomatis. Otomasi memastikan bahwa kontrol diterapkan dengan cara yang sama setiap saat untuk setiap sistem dan mereka juga menyediakan metode cepat untuk mengaudit sistem yang ada. Ada beberapa pilihan untuk otomasi:
- OpenSCAP
OpenSCAP adalah alat open source yang mengambil konten SCAP (file XML yang menjelaskan kontrol keamanan) dan menerapkan konten tersebut ke berbagai sistem. Sebagian besar konten yang tersedia saat ini tersedia untuk Red Hat Enterprise Linux dan CentOS, namun alat ini bekerja pada sistem Linux atau Windows manapun.
- ansible-hardening
Proyek ansible-hardening memberikan peran penting yang menerapkan kontrol keamanan ke beragam sistem operasi Linux. Ini juga bisa digunakan untuk mengaudit sistem yang ada. Setiap kontrol ditinjau ulang secara seksama untuk menentukan apakah hal itu dapat menyebabkan kerusakan pada sistem produksi. Kontrol didasarkan pada Red Hat Enterprise Linux 7 STIG.
Pengerasan sistem secara keseluruhan adalah proses yang menantang dan mungkin memerlukan sejumlah besar perubahan pada beberapa sistem. Beberapa perubahan ini bisa berdampak pada beban kerja produksi. Jika sistem tidak dapat sepenuhnya dikeraskan, dua perubahan berikut sangat dianjurkan untuk meningkatkan keamanan tanpa gangguan besar:
- Mandatory Access Control (MAC)
Kontrol akses wajib mempengaruhi semua pengguna di sistem, termasuk root, dan ini adalah tugas kernel untuk meninjau aktivitas terhadap kebijakan keamanan saat ini. Jika aktivitas tidak sesuai dengan kebijakan yang diijinkan, maka hal itu diblokir, bahkan untuk pengguna root. Tinjaulah diskusi di sVirt, SELinux, dan AppArmor di bawah ini untuk lebih jelasnya.
- Hapus paket dan stop service
Pastikan bahwa sistem memiliki jumlah paket terinstal dan layanan yang paling sedikit yang mungkin dijalankan. Melepaskan paket yang tidak dibutuhkan membuat tambalan lebih mudah dan mengurangi jumlah item pada sistem yang dapat menyebabkan pelanggaran. Menghentikan layanan yang tidak dibutuhkan mengecilkan permukaan serangan pada sistem dan membuatnya lebih sulit diserang.
Kami juga merekomendasikan langkah-langkah tambahan berikut untuk node produksi:
- Sistem file read-only
Gunakan sistem file read-only jika memungkinkan. Pastikan sistem berkas yang dapat ditulis tidak mengizinkan eksekusi. Ini bisa ditangani dengan opsi mount
noexec,nosuid, dannodevdi/etc/fstab.- Validasi sistem
Akhirnya, kernel node harus memiliki mekanisme untuk memvalidasi bahwa sisa node dimulai dalam keadaan baik yang diketahui. Ini menyediakan link yang diperlukan dari proses validasi booting untuk memvalidasi keseluruhan sistem. Langkah-langkah untuk melakukan hal ini adalah penerapan yang spesifik. Sebagai contoh, modul kernel dapat memverifikasi hash di atas blok yang terdiri dari sistem file sebelum memasangnya dm-verity.
Verifikasi runtime¶
Setelah node berjalan, kita perlu memastikan bahwa itu tetap dalam keadaan baik dari waktu ke waktu. Secara umum, ini mencakup pengelolaan konfigurasi dan pemantauan keamanan. Tujuan masing-masing daerah berbeda. Dengan memeriksa keduanya, kami mencapai kepastian yang lebih tinggi bahwa sistem beroperasi sesuai keinginan. Kami membahas manajemen konfigurasi di bagian manajemen, dan pemantauan keamanan di bawah ini.
Sistem pendeteksi intrusi¶
Alat deteksi intrusi berbasis host juga berguna untuk validasi otomatis internal awan. Ada berbagai alat deteksi intrusi berbasis host yang tersedia. Beberapa proyek open source yang tersedia secara bebas, sementara yang lainnya bersifat komersial. Biasanya alat ini menganalisis data dari berbagai sumber dan menghasilkan peringatan keamanan berdasarkan rangkaian aturan dan / atau pelatihan. Kemampuan khas meliputi analisis log, pengecekan integritas berkas, pemantauan kebijakan, dan deteksi rootkit. Lebih alat -- often custom -- yang canggih dapat memvalidasi bahwa image proses in-memory sesuai dengan on-disk yang dapat dieksekusi dan memvalidasi keadaan eksekusi dari proses yang sedang berjalan.
Salah satu keputusan kebijakan penting untuk arsitek awan adalah apa yang harus dilakukan dengan keluaran dari alat pemantau keamanan. Ada dua pilihan yang efektif. Yang pertama adalah mengingatkan manusia untuk menyelidiki dan / atau melakukan tindakan korektif. Ini bisa dilakukan dengan memasukkan peringatan keamanan di log atau event feed untuk administrator awan. Pilihan kedua adalah meminta agar awan mengambil beberapa bentuk tindakan perbaikan secara otomatis, selain mencatat kejadian tersebut. Tindakan perbaikan bisa mencakup apa saja dari menginstal ulang node untuk melakukan konfigurasi layanan kecil. Namun, tindakan perbaikan otomatis bisa jadi tantangan karena kemungkinan adanya positif palsu (false positive).
Positif palsu ((false positive) terjadi saat alat pemantau keamanan menghasilkan peringatan keamanan untuk peristiwa jinak. Karena sifat alat pemantauan keamanan, false positive pasti terjadi dari waktu ke waktu. Biasanya administrator awan dapat menyetel alat pemantauan keamanan untuk mengurangi false positive, namun ini juga dapat mengurangi tingkat deteksi keseluruhan secara bersamaan. Trade-off klasik ini harus dipahami dan dipertanggungjawabkan saat membuat sistem pemantauan keamanan di awan.
Pemilihan dan konfigurasi alat deteksi intrusi berbasis host sangat spesifik. Sebaiknya mulailah dengan mengeksplorasi proyek open source berikut yang menerapkan berbagai deteksi intrusi berbasis host dan fitur pemantauan file.
Alat deteksi intrusi jaringan melengkapi alat berbasis host. OpenStack tidak memiliki jaringan khusus IDS built-in, namun OpenStack Networking menyediakan mekanisme plug-in untuk mengaktifkan teknologi yang berbeda melalui Networking API. Arsitektur plug-in ini akan memungkinkan penyewa mengembangkan ekstensi API untuk memasukkan dan mengkonfigurasi layanan jaringan lanjutan mereka sendiri seperti firewall, sistem deteksi intrusi, atau VPN antara VM.
Serupa dengan alat berbasis host, pemilihan dan konfigurasi alat deteksi intrusi berbasis jaringan adalah pengerahan yang spesifik. Snort <https://www.snort.org/> __ adalah alat deteksi intrusi jaringan sumber terbuka terkemuka, dan tempat awal yang baik untuk belajar lebih banyak.
Ada beberapa pertimbangan keamanan penting untuk sistem deteksi intrusi berbasis jaringan dan host.
Penting untuk mempertimbangkan penempatan Network IDS di atas awan (misalnya, menambahkannya ke batas jaringan dan / atau jaringan sensitif). Penempatan tergantung pada lingkungan jaringan Anda namun pastikan untuk memantau dampak IDS terhadap layanan Anda bergantung pada tempat Anda memilih untuk menambahkannya. Lalu lintas terenkripsi, seperti TLS, biasanya tidak dapat diperiksa untuk konten oleh Network IDS. Namun, Network IDS masih dapat memberikan beberapa keuntungan dalam mengidentifikasi lalu lintas anomali yang tidak terenkripsi pada jaringan.
Dalam beberapa penerapan, mungkin diperlukan penambahan IDS berbasis host pada komponen sensitif pada jembatan domain keamanan. IDS berbasis host dapat mendeteksi aktivitas anomali dengan proses yang membahayakan atau tidak sah pada komponen. IDS harus mengirimkan informasi waspada dan log pada jaringan Management.
Pengerasan server¶
Server di awan, termasuk infrastruktur yang undercloud dan overcloud, harus menerapkan praktik terbaik pengerasan. Karena pengerasan OS dan server biasa terjadi, praktik terbaik yang berlaku termasuk namun tidak terbatas pada logging, batasan akun pengguna, dan pembaruan reguler tidak akan dibahas di sini, namun harus diterapkan pada semua infrastruktur.
File integrity management (FIM)¶
File integrity management (FIM) adalah metode untuk memastikan bahwa file seperti sistem sensitif atau file konfigurasi aplikasi tidak rusak atau diubah untuk memungkinkan akses yang tidak sah atau perilaku jahat. Hal ini dapat dilakukan melalui utilitas seperti Samhain yang akan membuat hash checksum dari sumber daya yang ditentukan dan kemudian memvalidasi hash secara berkala, atau melalui tool seperti DMVerity yang dapat mengambil hash dari perangkat blok dan akan memvalidasi hash tersebut sebagai mereka diakses oleh sistem sebelum dipresentasikan kepada pengguna.
Ini harus diletakkan di tempat untuk memantau dan melaporkan perubahan pada sistem, hypervisor, dan file konfigurasi aplikasi seperti /etc/pam.d/system-auth dan /etc/keystone/keystone.conf, serta modul kernel (seperti virtio). Praktik terbaik adalah dengan menggunakan perintah lsmod untuk menunjukkan apa yang secara teratur dimasukkan ke sistem untuk membantu menentukan apa yang seharusnya atau tidak boleh disertakan dalam pemeriksaan FIM.
