Compute schedulers¶
Compute uses the nova-scheduler service to determine how to dispatch
compute requests. For example, the nova-scheduler service determines on
which host or node a VM should launch. You can configure the scheduler through
a variety of options.
In the default configuration, this scheduler considers hosts that meet all the following criteria:
Are in the requested Availability Zone (
AvailabilityZoneFilter).Can service the request meaning the nova-compute service handling the target node is available and not disabled (
ComputeFilter).Satisfy the extra specs associated with the instance type (
ComputeCapabilitiesFilter).Satisfy any architecture, hypervisor type, or virtual machine mode properties specified on the instance’s image properties (
ImagePropertiesFilter).Are on a different host than other instances of a group (if requested) (
ServerGroupAntiAffinityFilter).Are in a set of group hosts (if requested) (
ServerGroupAffinityFilter).
The scheduler chooses a new host when an instance is migrated, resized, evacuated or unshelved after being shelve offloaded.
When evacuating instances from a host, the scheduler service honors the target host defined by the administrator on the nova evacuate command. If a target is not defined by the administrator, the scheduler determines the target host. For information about instance evacuation, see Evacuate instances.
Prefilters¶
As of the Rocky release, the scheduling process includes a prefilter step to increase the efficiency of subsequent stages. These prefilters are largely optional and serve to augment the request that is sent to placement to reduce the set of candidate compute hosts based on attributes that placement is able to answer for us ahead of time. In addition to the prefilters listed here, also see Tenant Isolation with Placement and Availability Zones with Placement.
Compute Image Type Support¶
New in version 20.0.0: (Train)
Starting in the Train release, there is a prefilter available for
excluding compute nodes that do not support the disk_format of the
image used in a boot request. This behavior is enabled by setting
scheduler.query_placement_for_image_type_support to
True. For example, the libvirt driver, when using ceph as an ephemeral
backend, does not support qcow2 images (without an expensive conversion
step). In this case (and especially if you have a mix of ceph and
non-ceph backed computes), enabling this feature will ensure that the
scheduler does not send requests to boot a qcow2 image to computes
backed by ceph.
Compute Disabled Status Support¶
New in version 20.0.0: (Train)
Starting in the Train release, there is a mandatory pre-filter
which will exclude disabled compute nodes similar to (but does not fully
replace) the ComputeFilter. Compute node resource providers with the
COMPUTE_STATUS_DISABLED trait will be excluded as scheduling candidates.
The trait is managed by the nova-compute service and should mirror the
disabled status on the related compute service record in the
os-services API. For example, if a compute service’s status is disabled,
the related compute node resource provider(s) for that service should have the
COMPUTE_STATUS_DISABLED trait. When the service status is enabled the
COMPUTE_STATUS_DISABLED trait shall be removed.
If the compute service is down when the status is changed, the trait will be
synchronized by the compute service when it is restarted. Similarly, if an
error occurs when trying to add or remove the trait on a given resource
provider, the trait will be synchronized when the update_available_resource
periodic task runs - which is controlled by the
update_resources_interval configuration option.
Isolate Aggregates¶
New in version 20.0.0: (Train)
Starting in the Train release, there is an optional placement pre-request filter Filtering hosts by isolating aggregates When enabled, the traits required in the server’s flavor and image must be at least those required in an aggregate’s metadata in order for the server to be eligible to boot on hosts in that aggregate.
The Filter Scheduler¶
Changed in version 23.0.0: (Wallaby)
Support for custom scheduler drivers was removed. Only the filter scheduler is now supported by nova.
Nova’s scheduler, known as the filter scheduler, supports filtering and weighting to make informed decisions on where a new instance should be created.
When the scheduler receives a request for a resource, it first applies filters to determine which hosts are eligible for consideration when dispatching a resource. Filters are binary: either a host is accepted by the filter, or it is rejected. Hosts that are accepted by the filter are then processed by a different algorithm to decide which hosts to use for that request, described in the Weights section.
Filtering
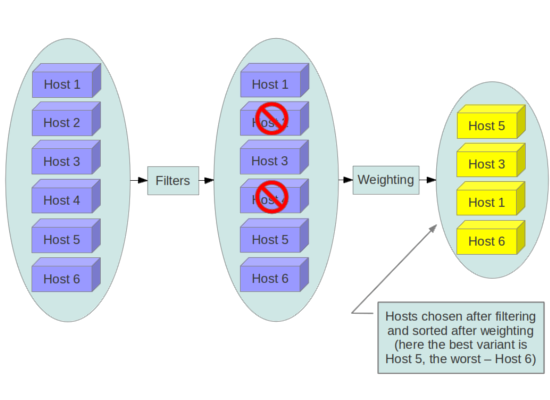
The filter_scheduler.available_filters config option
provides the Compute service with the list of the filters that are available
for use by the scheduler. The default setting specifies all of the filters that
are included with the Compute service. This configuration option can be
specified multiple times. For example, if you implemented your own custom
filter in Python called myfilter.MyFilter and you wanted to use both the
built-in filters and your custom filter, your nova.conf file would
contain:
[filter_scheduler]
available_filters = nova.scheduler.filters.all_filters
available_filters = myfilter.MyFilter
The filter_scheduler.enabled_filters configuration option
in nova.conf defines the list of filters that are applied by the
nova-scheduler service.
Filters¶
The following sections describe the available compute filters.
Filters are configured using the following config options:
filter_scheduler.available_filters- Defines filter classes made available to the scheduler. This setting can be used multiple times.filter_scheduler.enabled_filters- Of the available filters, defines those that the scheduler uses by default.
Each filter selects hosts in a different way and has different costs. The order
of filter_scheduler.enabled_filters affects scheduling
performance. The general suggestion is to filter out invalid hosts as soon as
possible to avoid unnecessary costs. We can sort
filter_scheduler.enabled_filters
items by their costs in reverse order. For example, ComputeFilter is better
before any resource calculating filters like NUMATopologyFilter.
In medium/large environments having AvailabilityZoneFilter before any capability or resource calculating filters can be useful.
AggregateImagePropertiesIsolation¶
Changed in version 12.0.0: (Liberty)
Prior to 12.0.0 Liberty, it was possible to specify and use arbitrary metadata with this filter. Starting in Liberty, nova only parses standard metadata. If you wish to use arbitrary metadata, consider using the AggregateInstanceExtraSpecsFilter filter instead.
Matches properties defined in an image’s metadata against those of aggregates to determine host matches:
If a host belongs to an aggregate and the aggregate defines one or more metadata that matches an image’s properties, that host is a candidate to boot the image’s instance.
If a host does not belong to any aggregate, it can boot instances from all images.
For example, the following aggregate myWinAgg has the Windows operating
system as metadata (named ‘windows’):
$ openstack aggregate show myWinAgg
+-------------------+----------------------------+
| Field | Value |
+-------------------+----------------------------+
| availability_zone | zone1 |
| created_at | 2017-01-01T15:36:44.000000 |
| deleted | False |
| deleted_at | None |
| hosts | ['sf-devel'] |
| id | 1 |
| name | myWinAgg |
| properties | os_distro='windows' |
| updated_at | None |
+-------------------+----------------------------+
In this example, because the following Win-2012 image has the windows
property, it boots on the sf-devel host (all other filters being equal):
$ openstack image show Win-2012
+------------------+------------------------------------------------------+
| Field | Value |
+------------------+------------------------------------------------------+
| checksum | ee1eca47dc88f4879d8a229cc70a07c6 |
| container_format | bare |
| created_at | 2016-12-13T09:30:30Z |
| disk_format | qcow2 |
| ... |
| name | Win-2012 |
| ... |
| properties | os_distro='windows' |
| ... |
You can configure the AggregateImagePropertiesIsolation filter by using the
following options in the nova.conf file:
filter_scheduler.aggregate_image_properties_isolation_namespacefilter_scheduler.aggregate_image_properties_isolation_separator
Note
This filter has limitations as described in bug 1677217 which are addressed in placement Filtering hosts by isolating aggregates request filter.
Refer to Host aggregates for more information.
AggregateInstanceExtraSpecsFilter¶
Matches properties defined in extra specs for an instance type against
admin-defined properties on a host aggregate. Works with specifications that
are scoped with aggregate_instance_extra_specs. Multiple values can be
given, as a comma-separated list. For backward compatibility, also works with
non-scoped specifications; this action is highly discouraged because it
conflicts with ComputeCapabilitiesFilter filter when you enable both
filters.
Refer to Host aggregates for more information.
AggregateIoOpsFilter¶
Filters host by disk allocation with a per-aggregate max_io_ops_per_host
value. If the per-aggregate value is not found, the value falls back to the
global setting defined by the
:oslo.config:option:`filter_scheduler.max_io_ops_per_host config option.
If the host is in more than one aggregate and more than one value is found, the
minimum value will be used.
Refer to Host aggregates and IoOpsFilter for more information.
AggregateMultiTenancyIsolation¶
Ensures hosts in tenant-isolated host aggregates will only be available to a
specified set of tenants. If a host is in an aggregate that has the
filter_tenant_id metadata key, the host can build instances from only that
tenant or comma-separated list of tenants. A host can be in different
aggregates. If a host does not belong to an aggregate with the metadata key,
the host can build instances from all tenants. This does not restrict the
tenant from creating servers on hosts outside the tenant-isolated aggregate.
For example, consider there are two available hosts for scheduling, HostA
and HostB. HostB is in an aggregate isolated to tenant X. A server
create request from tenant X will result in either HostA or HostB
as candidates during scheduling. A server create request from another tenant
Y will result in only HostA being a scheduling candidate since
HostA is not part of the tenant-isolated aggregate.
Note
There is a known limitation with the number of tenants that can be isolated per aggregate using this filter. This limitation does not exist, however, for the Tenant Isolation with Placement filtering capability added in the 18.0.0 Rocky release.
AggregateNumInstancesFilter¶
Filters host in an aggregate by number of instances with a per-aggregate
max_instances_per_host value. If the per-aggregate value is not found, the
value falls back to the global setting defined by the
filter_scheduler.max_instances_per_host config option.
If the host is in more than one aggregate and thus more than one value is
found, the minimum value will be used.
Refer to Host aggregates and NumInstancesFilter for more information.
AggregateTypeAffinityFilter¶
Filters hosts in an aggregate if the name of the instance’s flavor matches that
of the instance_type key set in the aggregate’s metadata or if the
instance_type key is not set.
The value of the instance_type metadata entry is a string that may contain
either a single instance_type name or a comma-separated list of
instance_type names, such as m1.nano or m1.nano,m1.small.
Note
Instance types are a historical name for flavors.
Refer to Host aggregates for more information.
AllHostsFilter¶
This is a no-op filter. It does not eliminate any of the available hosts.
AvailabilityZoneFilter¶
Filters hosts by availability zone. It passes hosts matching the availability zone specified in the instance properties. Use a comma to specify multiple zones. The filter will then ensure it matches any zone specified.
You must enable this filter for the scheduler to respect availability zones in requests.
Refer to Availability Zones for more information.
ComputeCapabilitiesFilter¶
Filters hosts by matching properties defined in flavor extra specs against compute
capabilities. If an extra specs key contains a colon (:), anything before
the colon is treated as a namespace and anything after the colon is treated as
the key to be matched. If a namespace is present and is not capabilities,
the filter ignores the namespace.
For example capabilities:cpu_info:features is a valid scope format.
For backward compatibility, the filter also treats the
extra specs key as the key to be matched if no namespace is present; this
action is highly discouraged because it conflicts with
AggregateInstanceExtraSpecsFilter filter when you enable both filters.
The extra specifications can have an operator at the beginning of the value
string of a key/value pair. If there is no operator specified, then a
default operator of s== is used. Valid operators are:
=(equal to or greater than as a number; same as vcpus case)==(equal to as a number)!=(not equal to as a number)>=(greater than or equal to as a number)<=(less than or equal to as a number)s==(equal to as a string)s!=(not equal to as a string)s>=(greater than or equal to as a string)s>(greater than as a string)s<=(less than or equal to as a string)s<(less than as a string)<in>(substring)<all-in>(all elements contained in collection)<or>(find one of these)
Examples are: >= 5, s== 2.1.0, <in> gcc, <all-in> aes mmx, and
<or> fpu <or> gpu
Some of attributes that can be used as useful key and their values contains:
free_ram_mb(compared with a number, values like>= 4096)free_disk_mb(compared with a number, values like>= 10240)host(compared with a string, values like<in> compute,s== compute_01)hypervisor_type(compared with a string, values likes== QEMU,s== ironic)hypervisor_version(compared with a number, values like>= 1005003,== 2000000)num_instances(compared with a number, values like<= 10)num_io_ops(compared with a number, values like<= 5)vcpus_total(compared with a number, values like= 48,>=24)vcpus_used(compared with a number, values like= 0,<= 10)
Some virt drivers support reporting CPU traits to the Placement service. With
that feature available, you should consider using traits in flavors instead of
ComputeCapabilitiesFilter because traits provide consistent naming for CPU
features in some virt drivers and querying traits is efficient. For more
details, refer to Feature Support Matrix,
Required traits,
Forbidden traits and
Report CPU features to the Placement service.
Also refer to Compute capabilities as traits.
ComputeFilter¶
Passes all hosts that are operational and enabled.
In general, you should always enable this filter.
DifferentHostFilter¶
Schedules the instance on a different host from a set of instances. To take
advantage of this filter, the requester must pass a scheduler hint, using
different_host as the key and a list of instance UUIDs as the value. This
filter is the opposite of the SameHostFilter.
For example, when using the openstack server create command, use the
--hint flag:
$ openstack server create \
--image cedef40a-ed67-4d10-800e-17455edce175 --flavor 1 \
--hint different_host=a0cf03a5-d921-4877-bb5c-86d26cf818e1 \
--hint different_host=8c19174f-4220-44f0-824a-cd1eeef10287 \
server-1
With the API, use the os:scheduler_hints key. For example:
{
"server": {
"name": "server-1",
"imageRef": "cedef40a-ed67-4d10-800e-17455edce175",
"flavorRef": "1"
},
"os:scheduler_hints": {
"different_host": [
"a0cf03a5-d921-4877-bb5c-86d26cf818e1",
"8c19174f-4220-44f0-824a-cd1eeef10287"
]
}
}
ImagePropertiesFilter¶
Filters hosts based on properties defined on the instance’s image. It passes hosts that can support the specified image properties contained in the instance. Properties include the architecture, hypervisor type, hypervisor version, and virtual machine mode.
For example, an instance might require a host that runs an ARM-based processor, and QEMU as the hypervisor. You can decorate an image with these properties by using:
$ openstack image set --architecture arm --property img_hv_type=qemu \
img-uuid
The image properties that the filter checks for are:
hw_architectureDescribes the machine architecture required by the image. Examples are
i686,x86_64,arm, andppc64.Changed in version 12.0.0: (Liberty)
This was previously called
architecture.img_hv_typeDescribes the hypervisor required by the image. Examples are
qemuandhyperv.Note
qemuis used for both QEMU and KVM hypervisor types.Changed in version 12.0.0: (Liberty)
This was previously called
hypervisor_type.img_hv_requested_versionDescribes the hypervisor version required by the image. The property is supported for HyperV hypervisor type only. It can be used to enable support for multiple hypervisor versions, and to prevent instances with newer HyperV tools from being provisioned on an older version of a hypervisor. If available, the property value is compared to the hypervisor version of the compute host.
To filter the hosts by the hypervisor version, add the
img_hv_requested_versionproperty on the image as metadata and pass an operator and a required hypervisor version as its value:$ openstack image set --property hypervisor_type=hyperv --property \ hypervisor_version_requires=">=6000" img-uuid
Changed in version 12.0.0: (Liberty)
This was previously called
hypervisor_version_requires.hw_vm_modedescribes the hypervisor application binary interface (ABI) required by the image. Examples are
xenfor Xen 3.0 paravirtual ABI,hvmfor native ABI, andexefor container virt executable ABI.Changed in version 12.0.0: (Liberty)
This was previously called
vm_mode.
IsolatedHostsFilter¶
Allows the admin to define a special (isolated) set of images and a special
(isolated) set of hosts, such that the isolated images can only run on the
isolated hosts, and the isolated hosts can only run isolated images. The flag
restrict_isolated_hosts_to_isolated_images can be used to force isolated
hosts to only run isolated images.
The logic within the filter depends on the
restrict_isolated_hosts_to_isolated_images config option, which defaults
to True. When True, a volume-backed instance will not be put on an isolated
host. When False, a volume-backed instance can go on any host, isolated or
not.
The admin must specify the isolated set of images and hosts using the
filter_scheduler.isolated_hosts and
filter_scheduler.isolated_images config options.
For example:
[filter_scheduler]
isolated_hosts = server1, server2
isolated_images = 342b492c-128f-4a42-8d3a-c5088cf27d13, ebd267a6-ca86-4d6c-9a0e-bd132d6b7d09
You can also specify that isolated host only be used for specific isolated
images using the
filter_scheduler.restrict_isolated_hosts_to_isolated_images
config option.
IoOpsFilter¶
Filters hosts by concurrent I/O operations on it. Hosts with too many
concurrent I/O operations will be filtered out. The
filter_scheduler.max_io_ops_per_host option specifies the
maximum number of I/O intensive instances allowed to run on a host.
A host will be ignored by the scheduler if more than
filter_scheduler.max_io_ops_per_host instances in build,
resize, snapshot, migrate, rescue or unshelve task states are running on it.
JsonFilter¶
Warning
This filter is not enabled by default and not comprehensively tested, and thus could fail to work as expected in non-obvious ways. Furthermore, the filter variables are based on attributes of the HostState class which could change from release to release so usage of this filter is generally not recommended. Consider using other filters such as the ImagePropertiesFilter or traits-based scheduling.
Allows a user to construct a custom filter by passing a scheduler hint in JSON format. The following operators are supported:
=<>in<=>=notorand
Unlike most other filters that rely on information provided via scheduler hints, this filter filters on attributes in the HostState class such as the following variables:
$free_ram_mb$free_disk_mb$hypervisor_hostname$total_usable_ram_mb$vcpus_total$vcpus_used
Using the openstack server create command, use the --hint flag:
$ openstack server create --image 827d564a-e636-4fc4-a376-d36f7ebe1747 \
--flavor 1 --hint query='[">=","$free_ram_mb",1024]' server1
With the API, use the os:scheduler_hints key:
{
"server": {
"name": "server-1",
"imageRef": "cedef40a-ed67-4d10-800e-17455edce175",
"flavorRef": "1"
},
"os:scheduler_hints": {
"query": "[\">=\",\"$free_ram_mb\",1024]"
}
}
MetricsFilter¶
Use in collaboration with the MetricsWeigher weigher. Filters hosts that
do not report the metrics specified in
metrics.weight_setting, thus ensuring the metrics
weigher will not fail due to these hosts.
NUMATopologyFilter¶
Filters hosts based on the NUMA topology that was specified for the instance
through the use of flavor extra_specs in combination with the image
properties, as described in detail in CPU topologies. The filter
will try to match the exact NUMA cells of the instance to those of the host. It
will consider the standard over-subscription limits for each host NUMA cell,
and provide limits to the compute host accordingly.
This filter is essential if using instances with features that rely on NUMA, such as instance NUMA topologies or CPU pinning.
Note
If instance has no topology defined, it will be considered for any host. If instance has a topology defined, it will be considered only for NUMA capable hosts.
NumInstancesFilter¶
Filters hosts based on the number of instances running on them. Hosts that have
more instances running than specified by the
filter_scheduler.max_instances_per_host config option are
filtered out.
PciPassthroughFilter¶
The filter schedules instances on a host if the host has devices that meet the
device requests in the extra_specs attribute for the flavor.
This filter is essential if using instances with PCI device requests or where SR-IOV-based networking is in use on hosts.
SameHostFilter¶
Schedules an instance on the same host as all other instances in a set of
instances. To take advantage of this filter, the requester must pass a
scheduler hint, using same_host as the key and a list of instance UUIDs as
the value. This filter is the opposite of the DifferentHostFilter.
For example, when using the openstack server create command, use the
--hint flag:
$ openstack server create \
--image cedef40a-ed67-4d10-800e-17455edce175 --flavor 1 \
--hint same_host=a0cf03a5-d921-4877-bb5c-86d26cf818e1 \
--hint same_host=8c19174f-4220-44f0-824a-cd1eeef10287 \
server-1
With the API, use the os:scheduler_hints key:
{
"server": {
"name": "server-1",
"imageRef": "cedef40a-ed67-4d10-800e-17455edce175",
"flavorRef": "1"
},
"os:scheduler_hints": {
"same_host": [
"a0cf03a5-d921-4877-bb5c-86d26cf818e1",
"8c19174f-4220-44f0-824a-cd1eeef10287"
]
}
}
ServerGroupAffinityFilter¶
Restricts instances belonging to a server group to the same host(s). To take
advantage of this filter, the requester must create a server group with an
affinity policy, and pass a scheduler hint, using group as the key and
the server group UUID as the value.
For example, when using the openstack server create command, use the
--hint flag:
$ openstack server group create --policy affinity group-1
$ openstack server create --image IMAGE_ID --flavor 1 \
--hint group=SERVER_GROUP_UUID server-1
ServerGroupAntiAffinityFilter¶
Restricts instances belonging to a server group to separate hosts.
To take advantage of this filter, the requester must create a
server group with an anti-affinity policy, and pass a scheduler hint, using
group as the key and the server group UUID as the value.
For example, when using the openstack server create command, use the
--hint flag:
$ openstack server group create --policy anti-affinity group-1
$ openstack server create --image IMAGE_ID --flavor 1 \
--hint group=SERVER_GROUP_UUID server-1
SimpleCIDRAffinityFilter¶
Todo
Does this filter still work with neutron?
Schedules the instance based on host IP subnet range. To take advantage of this filter, the requester must specify a range of valid IP address in CIDR format, by passing two scheduler hints:
build_near_host_ipThe first IP address in the subnet (for example,
192.168.1.1)cidrThe CIDR that corresponds to the subnet (for example,
/24)
When using the openstack server create command, use the --hint
flag. For example, to specify the IP subnet 192.168.1.1/24:
$ openstack server create \
--image cedef40a-ed67-4d10-800e-17455edce175 --flavor 1 \
--hint build_near_host_ip=192.168.1.1 --hint cidr=/24 \
server-1
With the API, use the os:scheduler_hints key:
{
"server": {
"name": "server-1",
"imageRef": "cedef40a-ed67-4d10-800e-17455edce175",
"flavorRef": "1"
},
"os:scheduler_hints": {
"build_near_host_ip": "192.168.1.1",
"cidr": "24"
}
}
Weights¶
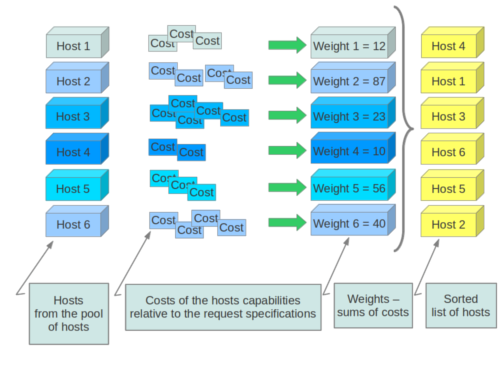
When resourcing instances, the filter scheduler filters and weights each host in the list of acceptable hosts. Each time the scheduler selects a host, it virtually consumes resources on it and subsequent selections are adjusted accordingly. This process is useful when the customer asks for the same large amount of instances because a weight is computed for each requested instance.
In order to prioritize one weigher against another, all the weighers have to define a multiplier that will be applied before computing the weight for a node. All the weights are normalized beforehand so that the multiplier can be applied easily.Therefore the final weight for the object will be:
weight = w1_multiplier * norm(w1) + w2_multiplier * norm(w2) + ...
Hosts are weighted based on the following config options:
RAMWeigher¶
Compute weight based on available RAM on the compute node.
Sort with the largest weight winning. If the multiplier,
filter_scheduler.ram_weight_multiplier, is negative, the
host with least RAM available will win (useful for stacking hosts, instead
of spreading).
Starting with the Stein release, if per-aggregate value with the key
ram_weight_multiplier is found, this
value would be chosen as the ram weight multiplier. Otherwise, it will fall
back to the filter_scheduler.ram_weight_multiplier.
If more than one value is found for a host in aggregate metadata, the minimum
value will be used.
CPUWeigher¶
Compute weight based on available vCPUs on the compute node.
Sort with the largest weight winning. If the multiplier,
filter_scheduler.cpu_weight_multiplier, is negative, the
host with least CPUs available will win (useful for stacking hosts, instead
of spreading).
Starting with the Stein release, if per-aggregate value with the key
cpu_weight_multiplier is found, this
value would be chosen as the cpu weight multiplier. Otherwise, it will fall
back to the filter_scheduler.cpu_weight_multiplier. If
more than one value is found for a host in aggregate metadata, the minimum
value will be used.
DiskWeigher¶
Hosts are weighted and sorted by free disk space with the largest weight winning. If the multiplier is negative, the host with less disk space available will win (useful for stacking hosts, instead of spreading).
Starting with the Stein release, if per-aggregate value with the key
disk_weight_multiplier is found, this
value would be chosen as the disk weight multiplier. Otherwise, it will fall
back to the filter_scheduler.disk_weight_multiplier. If
more than one value is found for a host in aggregate metadata, the minimum value
will be used.
MetricsWeigher¶
This weigher can compute the weight based on the compute node
host’s various metrics. The to-be weighed metrics and their weighing ratio
are specified using the metrics.weight_setting config
option. For example:
[metrics]
weight_setting = name1=1.0, name2=-1.0
You can specify the metrics that are required, along with the weight of those
that are not and are not available using the
metrics.required and
metrics.weight_of_unavailable config options,
respectively.
Starting with the Stein release, if per-aggregate value with the key
metrics_weight_multiplier is found, this value would be chosen as the
metrics weight multiplier. Otherwise, it will fall back to the
metrics.weight_multiplier. If more than
one value is found for a host in aggregate metadata, the minimum value will
be used.
IoOpsWeigher¶
The weigher can compute the weight based on the compute node host’s workload.
This is calculated by examining the number of instances in the building
vm_state or in one of the following task_state‘s:
resize_migrating, rebuilding, resize_prep, image_snapshot,
image_backup, rescuing, or unshelving.
The default is to preferably choose light workload compute hosts. If the
multiplier is positive, the weigher prefers choosing heavy workload compute
hosts, the weighing has the opposite effect of the default.
Starting with the Stein release, if per-aggregate value with the key
io_ops_weight_multiplier is found, this
value would be chosen as the IO ops weight multiplier. Otherwise, it will fall
back to the filter_scheduler.io_ops_weight_multiplier.
If more than one value is found for a host in aggregate metadata, the minimum
value will be used.
PCIWeigher¶
Compute a weighting based on the number of PCI devices on the host and the number of PCI devices requested by the instance. For example, given three hosts - one with a single PCI device, one with many PCI devices, and one with no PCI devices - nova should prioritise these differently based on the demands of the instance. If the instance requests a single PCI device, then the first of the hosts should be preferred. Similarly, if the instance requests multiple PCI devices, then the second of these hosts would be preferred. Finally, if the instance does not request a PCI device, then the last of these hosts should be preferred.
For this to be of any value, at least one of the PciPassthroughFilter or NUMATopologyFilter filters must be enabled.
Starting with the Stein release, if per-aggregate value with the key
pci_weight_multiplier is found, this
value would be chosen as the pci weight multiplier. Otherwise, it will fall
back to the filter_scheduler.pci_weight_multiplier.
If more than one value is found for a host in aggregate metadata, the
minimum value will be used.
Important
Only positive values are allowed for the multiplier of this weigher as a negative value would force non-PCI instances away from non-PCI hosts, thus, causing future scheduling issues.
ServerGroupSoftAffinityWeigher¶
The weigher can compute the weight based on the number of instances that run on the same server group. The largest weight defines the preferred host for the new instance. For the multiplier only a positive value is allowed for the calculation.
Starting with the Stein release, if per-aggregate value with the key
soft_affinity_weight_multiplier is
found, this value would be chosen as the soft affinity weight multiplier.
Otherwise, it will fall back to the
filter_scheduler.soft_affinity_weight_multiplier.
If more than one value is found for a host in aggregate metadata, the
minimum value will be used.
ServerGroupSoftAntiAffinityWeigher¶
The weigher can compute the weight based on the number of instances that run on the same server group as a negative value. The largest weight defines the preferred host for the new instance. For the multiplier only a positive value is allowed for the calculation.
Starting with the Stein release, if per-aggregate value with the key
soft_anti_affinity_weight_multiplier is found, this value would be chosen
as the soft anti-affinity weight multiplier. Otherwise, it will fall back to
the
filter_scheduler.soft_anti_affinity_weight_multiplier.
If more than one value is found for a host in aggregate metadata, the minimum
value will be used.
BuildFailureWeigher¶
Weigh hosts by the number of recent failed boot attempts. It considers the build failure counter and can negatively weigh hosts with recent failures. This avoids taking computes fully out of rotation.
Starting with the Stein release, if per-aggregate value with the key
build_failure_weight_multiplier is found, this value would be chosen as the
build failure weight multiplier. Otherwise, it will fall back to the
filter_scheduler.build_failure_weight_multiplier. If
more than one value is found for a host in aggregate metadata, the minimum
value will be used.
Important
The filter_scheduler.build_failure_weight_multiplier
option defaults to a very high value. This is intended to offset weight
given by other enabled weighers due to available resources, giving this
weigher priority. However, not all build failures imply a problem with the
host itself - it could be user error - but the failure will still be
counted. If you find hosts are frequently reporting build failures and
effectively being excluded during scheduling, you may wish to lower the
value of the multiplier.
CrossCellWeigher¶
New in version 21.0.0: (Ussuri)
Weighs hosts based on which cell they are in. “Local” cells are preferred when moving an instance.
If per-aggregate value with the key cross_cell_move_weight_multiplier is
found, this value would be chosen as the cross-cell move weight multiplier.
Otherwise, it will fall back to the
filter_scheduler.cross_cell_move_weight_multiplier. If
more than one value is found for a host in aggregate metadata, the minimum
value will be used.
Utilization-aware scheduling¶
Warning
This feature is poorly tested and may not work as expected. It may be removed in a future release. Use at your own risk.
It is possible to schedule instances using advanced scheduling decisions. These
decisions are made based on enhanced usage statistics encompassing data like
memory cache utilization, memory bandwidth utilization, or network bandwidth
utilization. This is disabled by default. The administrator can configure how
the metrics are weighted in the configuration file by using the
metrics.weight_setting config option. For example to
configure metric1 with ratio1 and metric2 with ratio2:
[metrics]
weight_setting = "metric1=ratio1, metric2=ratio2"
Allocation ratios¶
Allocation ratios allow for the overcommit of host resources. The following configuration options exist to control allocation ratios per compute node to support this overcommit of resources:
cpu_allocation_ratioallows overriding theVCPUinventory allocation ratio for a compute noderam_allocation_ratioallows overriding theMEMORY_MBinventory allocation ratio for a compute nodedisk_allocation_ratioallows overriding theDISK_GBinventory allocation ratio for a compute node
Prior to the 19.0.0 Stein release, if left unset, the cpu_allocation_ratio
defaults to 16.0, the ram_allocation_ratio defaults to 1.5, and the
disk_allocation_ratio defaults to 1.0.
Starting with the 19.0.0 Stein release, the following configuration options control the initial allocation ratio values for a compute node:
initial_cpu_allocation_ratiothe initial VCPU inventory allocation ratio for a new compute node record, defaults to 16.0initial_ram_allocation_ratiothe initial MEMORY_MB inventory allocation ratio for a new compute node record, defaults to 1.5initial_disk_allocation_ratiothe initial DISK_GB inventory allocation ratio for a new compute node record, defaults to 1.0
Starting with the 27.0.0 Antelope release, the following default values are used for the initial allocation ratio values for a compute node:
initial_cpu_allocation_ratiothe initial VCPU inventory allocation ratio for a new compute node record, defaults to 4.0initial_ram_allocation_ratiothe initial MEMORY_MB inventory allocation ratio for a new compute node record, defaults to 1.0initial_disk_allocation_ratiothe initial DISK_GB inventory allocation ratio for a new compute node record, defaults to 1.0
Scheduling considerations¶
The allocation ratio configuration is used both during reporting of compute node resource provider inventory to the placement service and during scheduling.
Usage scenarios¶
Since allocation ratios can be set via nova configuration and the placement API, it can be confusing to know which should be used. This really depends on your scenario. A few common scenarios are detailed here.
When the deployer wants to always set an override value for a resource on a compute node, the deployer should ensure that the
DEFAULT.cpu_allocation_ratio,DEFAULT.ram_allocation_ratioandDEFAULT.disk_allocation_ratioconfiguration options are set to a non-None value. This will make thenova-computeservice overwrite any externally-set allocation ratio values set via the placement REST API.When the deployer wants to set an initial value for a compute node allocation ratio but wants to allow an admin to adjust this afterwards without making any configuration file changes, the deployer should set the
DEFAULT.initial_cpu_allocation_ratio,DEFAULT.initial_ram_allocation_ratioandDEFAULT.initial_disk_allocation_ratioconfiguration options and then manage the allocation ratios using the placement REST API (or osc-placement command line interface). For example:$ openstack resource provider inventory set \ --resource VCPU:allocation_ratio=1.0 \ --amend 815a5634-86fb-4e1e-8824-8a631fee3e06
When the deployer wants to always use the placement API to set allocation ratios, then the deployer should ensure that the
DEFAULT.cpu_allocation_ratio,DEFAULT.ram_allocation_ratioandDEFAULT.disk_allocation_ratioconfiguration options are set to a None and then manage the allocation ratios using the placement REST API (or osc-placement command line interface).This scenario is the workaround for bug 1804125.
Changed in version 19.0.0: (Stein)
The DEFAULT.initial_cpu_allocation_ratio,
DEFAULT.initial_ram_allocation_ratio and
DEFAULT.initial_disk_allocation_ratio configuration
options were introduced in Stein. Prior to this release, setting any of
DEFAULT.cpu_allocation_ratio,
DEFAULT.ram_allocation_ratio or
DEFAULT.disk_allocation_ratio to a non-null value
would ensure the user-configured value was always overridden.
Hypervisor-specific considerations¶
Nova provides three configuration options that can be used to set aside some number of resources that will not be consumed by an instance, whether these resources are overcommitted or not:
Some virt drivers may benefit from the use of these options to account for hypervisor-specific overhead.
- HyperV
Hyper-V creates a VM memory file on the local disk when an instance starts. The size of this file corresponds to the amount of RAM allocated to the instance.
You should configure the
reserved_host_disk_mbconfig option to account for this overhead, based on the amount of memory available to instances.
Cells considerations¶
By default cells are enabled for scheduling new instances but they can be disabled (new schedules to the cell are blocked). This may be useful for users while performing cell maintenance, failures or other interventions. It is to be noted that creating pre-disabled cells and enabling/disabling existing cells should either be followed by a restart or SIGHUP of the nova-scheduler service for the changes to take effect.
Command-line interface¶
The nova-manage command-line client supports the cell-disable related commands. To enable or disable a cell, use nova-manage cell_v2 update_cell and to create pre-disabled cells, use nova-manage cell_v2 create_cell. See the Cells v2 Commands man page for details on command usage.
Compute capabilities as traits¶
New in version 19.0.0: (Stein)
The nova-compute service will report certain COMPUTE_* traits based on
its compute driver capabilities to the placement service. The traits will be
associated with the resource provider for that compute service. These traits
can be used during scheduling by configuring flavors with
Required traits or
Forbidden traits. For example, if you
have a host aggregate with a set of compute nodes that support multi-attach
volumes, you can restrict a flavor to that aggregate by adding the
trait:COMPUTE_VOLUME_MULTI_ATTACH=required extra spec to the flavor and
then restrict the flavor to the aggregate
as normal.
Here is an example of a libvirt compute node resource provider that is
exposing some CPU features as traits, driver capabilities as traits, and a
custom trait denoted by the CUSTOM_ prefix:
$ openstack --os-placement-api-version 1.6 resource provider trait list \
> d9b3dbc4-50e2-42dd-be98-522f6edaab3f --sort-column name
+---------------------------------------+
| name |
+---------------------------------------+
| COMPUTE_DEVICE_TAGGING |
| COMPUTE_NET_ATTACH_INTERFACE |
| COMPUTE_NET_ATTACH_INTERFACE_WITH_TAG |
| COMPUTE_TRUSTED_CERTS |
| COMPUTE_VOLUME_ATTACH_WITH_TAG |
| COMPUTE_VOLUME_EXTEND |
| COMPUTE_VOLUME_MULTI_ATTACH |
| CUSTOM_IMAGE_TYPE_RBD |
| HW_CPU_X86_MMX |
| HW_CPU_X86_SSE |
| HW_CPU_X86_SSE2 |
| HW_CPU_X86_SVM |
+---------------------------------------+
Rules
There are some rules associated with capability-defined traits.
The compute service “owns” these traits and will add/remove them when the
nova-computeservice starts and when theupdate_available_resourceperiodic task runs, with run intervals controlled by config optionupdate_resources_interval.The compute service will not remove any custom traits set on the resource provider externally, such as the
CUSTOM_IMAGE_TYPE_RBDtrait in the example above.If compute-owned traits are removed from the resource provider externally, for example by running
openstack resource provider trait delete <rp_uuid>, the compute service will add its traits again on restart or SIGHUP.If a compute trait is set on the resource provider externally which is not supported by the driver, for example by adding the
COMPUTE_VOLUME_EXTENDtrait when the driver does not support that capability, the compute service will automatically remove the unsupported trait on restart or SIGHUP.Compute capability traits are standard traits defined in the os-traits library.
Further information on capabilities and traits can be found in the Technical Reference Deep Dives section.
Writing Your Own Filter¶
To create your own filter, you must inherit from BaseHostFilter and
implement one method: host_passes. This method should return True if a
host passes the filter and return False elsewhere. It takes two parameters:
the
HostStateobject allows to get attributes of the hostthe
RequestSpecobject describes the user request, including the flavor, the image and the scheduler hints
For further details about each of those objects and their corresponding
attributes, refer to the codebase (at least by looking at the other filters
code) or ask for help in the #openstack-nova IRC channel.
In addition, if your custom filter uses non-standard extra specs, you must
register validators for these extra specs. Examples of validators can be found
in the nova.api.validation.extra_specs module. These should be registered
via the nova.api.extra_spec_validator entrypoint.
The module containing your custom filter(s) must be packaged and available in the same environment(s) that the nova controllers, or specifically the nova-scheduler and nova-api services, are available in. As an example, consider the following sample package, which is the minimal structure for a standard, setuptools-based Python package:
acmefilter/
acmefilter/
__init__.py
validators.py
setup.py
Where __init__.py contains:
from oslo_log import log as logging
from nova.scheduler import filters
LOG = logging.getLogger(__name__)
class AcmeFilter(filters.BaseHostFilter):
def host_passes(self, host_state, spec_obj):
extra_spec = spec_obj.flavor.extra_specs.get('acme:foo')
LOG.info("Extra spec value was '%s'", extra_spec)
# do meaningful stuff here...
return True
validators.py contains:
from nova.api.validation.extra_specs import base
def register():
validators = [
base.ExtraSpecValidator(
name='acme:foo',
description='My custom extra spec.'
value={
'type': str,
'enum': [
'bar',
'baz',
],
},
),
]
return validators
setup.py contains:
from setuptools import setup
setup(
name='acmefilter',
version='0.1',
description='My custom filter',
packages=[
'acmefilter'
],
entry_points={
'nova.api.extra_spec_validators': [
'acme = acmefilter.validators',
],
},
)
To enable this, you would set the following in nova.conf:
[filter_scheduler]
available_filters = nova.scheduler.filters.all_filters
available_filters = acmefilter.AcmeFilter
enabled_filters = ComputeFilter,AcmeFilter
Note
You must add custom filters to the list of available filters using the
filter_scheduler.available_filters config option in
addition to enabling them via the
filter_scheduler.enabled_filters config option. The
default nova.scheduler.filters.all_filters value for the former only
includes the filters shipped with nova.
With these settings, all of the standard nova filters and the custom
AcmeFilter filter are available to the scheduler, but just the
ComputeFilter and AcmeFilter will be used on each request.
Writing your own weigher¶
To create your own weigher, you must inherit from BaseHostFilter
A weigher can implement both the weight_multiplier and _weight_object
methods or just implement the weight_objects method. weight_objects
method is overridden only if you need access to all objects in order to
calculate weights, and it just return a list of weights, and not modify the
weight of the object directly, since final weights are normalized and computed
by weight.BaseWeightHandler.
