Pacemaker アーキテクチャー¶
クラスターマネージャーとは?¶
クラスターは、その中心において、複数のセットのマシン間で関連するサービスのスタートアップとリカバリーを調整する機能を持つ、分散有限状態マシンです。
いくつかのマシンの障害に耐えられる分散アプリケーションやレプリケーションでも、クラスターマネージャーが以下の機能を持つので、クラスターマネージャーによる恩恵があります。
スタックにある他のアプリケーションの認識
systemd のような SYS-V init の代替は、複雑なスタックのサービスにおける順序を守った復旧を提供できますが、復旧は 1 台のマシンに限定され、他のマシンにおいて起きたことを把握できません。このコンテキストは、ローカル障害間の違いを判断し、全サイト障害から正常に起動して復旧するために重要です。
他のマシンにあるインスタンスの把握
RabbitMQ や Galera などのサービスは、複雑な起動順番を持ちます。クラスター内の全マシンに渡り、起動処理の協調動作を必要とし、しばしば順番に実行する必要があります。とくに、サイト全体の障害後、最後にアクティブにするマシンを判断する必要のあるシャットダウンのときに当てはまります。
クォーラム の共有実装と計算
システムのすべてのメンバーが、誰がメンバーであるか、それらが多数派かどうかについて、同じビューを共有することが非常に重要です。これを行う障害は、かなりすぐに スプリットブレイン 状態を引き起こします。これは、システムの別々の部分が、別々な互換性のない方向を引き込むことです。
フェンシングによるデータ完全性 (応答なしプロセスが何もしていないことを意味します)
単一アプリケーションは、マシンの障害とマシン上のアプリケーション障害の違いを十分に理解できません。一般的なプラクティスは、マシンが停止したと仮定して、動作し続けることです。しかしながら、これは非常にリスクがあります。はぐれたプロセスやマシンがリクエストに応答し続け、一般的に大破壊を引き起こし続ける可能性があります。より安全なアプローチは、継続する前にマシンをフェンス (隔離) するために、リモートアクセス可能な電源スイッチ、ネットワークスイッチ、SAN コントローラーを使用することです。
障害インスタンスの自動復旧
アプリケーションは、いくつかのインスタンスが故障した後も動作できますが、要求されたリクエスト量を処理するための十分な容量がないかもしれません。クラスターは自動的に故障したインスタンスを復旧して、さらなる負荷が障害を引き起こさないようにできます。
これらの理由のため、Pacemaker のようなクラスターマネージャーを使用することを強く推奨します。
デプロイフレーバー¶
3 種類の Pacemaker アーキテクチャーを導入できます。2 つの極端なものは、Collapsed (すべてのコンポーネントがすべてのノードで動作する) と Segregated (すべてのコンポーネントが自身の 3+ ノードクラスターで動作する) です。
選択するフレーバーに関わらず、クラスターは quorum の利点を得るために、少なくとも 3 ノードを持つことを推奨します。
障害がクラスターを 2 つ以上のパーティションに分割した場合、クォーラムは重要になります。この状況では、システムの多数派のメンバーが、少数派を確実に (フェンス経由で) 停止させ、ホストリソースを継続することを確実にしたいでしょう。2 ノードクラスターの場合、多数派になる側がなく、両方がお互いをフェンスする状況、または両方が同じサービスを実行する状況になる可能性があります。これはデータ破損を引き起こします。
偶数のホストを持つクラスターは、同じような問題に苦しみます。単一のネットワーク障害により、どちらの側も多数派になれない N:N 分断を簡単に引き起こす可能性があります。この理由により、スケールアップするとき、奇数個のクラスターメンバーを推奨します。
クラスターのメンバーを 16 まで持てます (これは、corosync をよりスケールさせる機能による、現在の制限です)。極端な場合、32 や 64 までのノードさえ利用できますが、十分にテストされていません。
Collapsed¶
この折りたたまれた設定では、すべてのコンポーネントが動作する、3 つ以上のノードを持つシングルクラスターがあります。
このシナリオは、より高性能ならば、より少ないマシンを必要とする利点があります。加えて、シングルクラスターの一部になることにより、コンポーネント間の順序依存関係を正確にモデル化できます。
このシナリオは以下のように可視化できます。
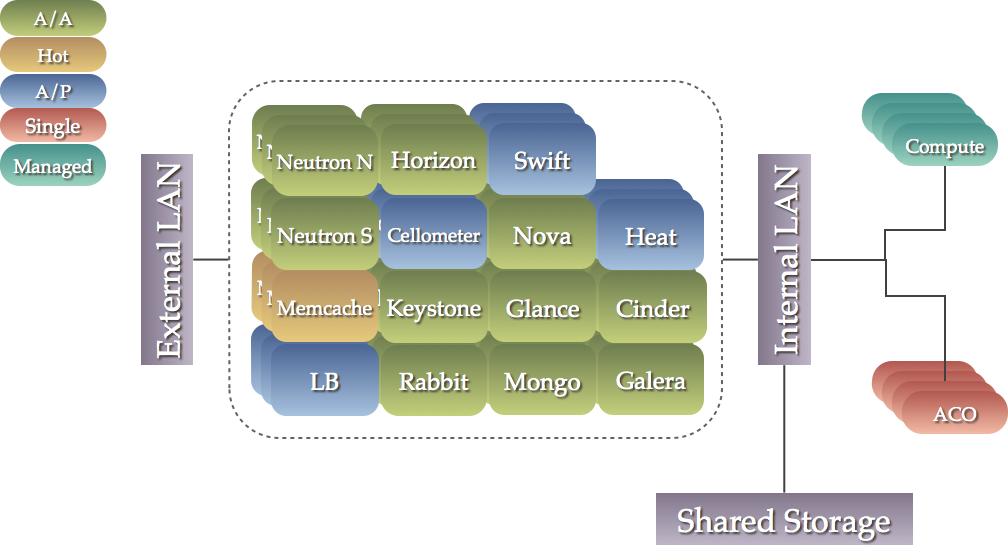
より少数の高性能なマシンを好む場合、この選択肢を選択するでしょう。
これは最も一般的なオプションで、ここにドキュメント化します。
Segregated¶
この設定では、各サービスが 3 以上のノードの専用クラスターで動作します。
この方法の利点は、コンポーネント間の物理的な隔離、特定のコンポーネントへのキャパシティーの追加です。
より多数の低性能なマシンを好む場合、この選択肢を選択するでしょう。
このシナリオは、以下のように可視化できます。以下の各ボックスは 3 つ以上のゲストのクラスターを表します。
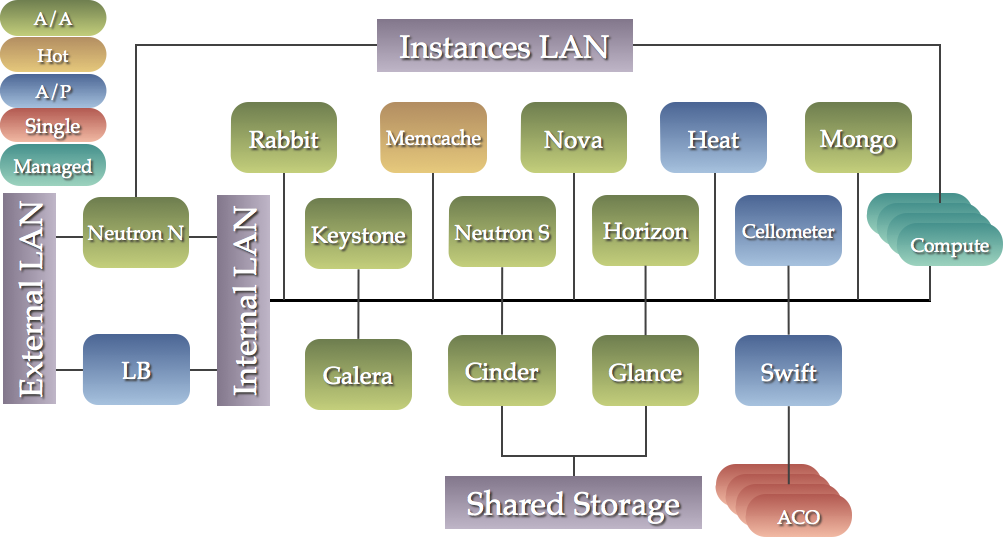
Mixed¶
1 つ以上のコンポーネントに対して、別々のアプローチをとることができますが、ボトルネックになり、思い出すことが難しいアプローチを使用する可能性があります。
プロキシーサーバー¶
このスタックのほぼすべてのサービスは、プロキシーする恩恵を受けられます。プロキシーサーバを使用することにより、以下の機能が提供されます。
負荷分散
ほとんどのサービスがアクティブ/アクティブ機能で動作できます。しかしながら、通常は分散されたリクエストが利用できるインスタンスのどれかになる外部機能が必要になります。プロキシーサーバーはこの役割になれます。
API 分離
すべての API アクセスをプロキシー経由で送信することにより、サービスの相互依存関係を明確に識別できます。キャパシティーを必要に応じて増やすために、それらを
localhostから別の場所に移動できます。ノードの追加と削除を簡単化したプロセス
すべての API アクセスがプロキシーに向けられているので、ノードの追加や削除は、他のサービスの設定に影響を与えません。これにより、プロキシーが新しいマシン群に通信を向ける前に、それらを独立した環境において設定してテストする、アップグレードシナリオにおいて非常に役立ちます。
高度な障害検出
プロキシーは、サービスの障害を検知するための 2 番目の機構として設定できます。(長く複製から外れているなど) デグレード状態にあるノードを探して、それらを除外するよう設定することもできます。
以下のコンポーネントは、現在、プロキシサーバーの利用による利点はありません。
- RabbitMQ
- Memcached
- MongoDB
ロードバランサーとして HAProxy を推奨しますが、マーケットプレースにさまざまな同等品があります。
Generally, we use round-robin to distribute load amongst instances of
active/active services. Alternatively, Galera uses stick-table options
to ensure that incoming connection to virtual IP (VIP) are directed to only one
of the available back ends. This helps avoid lock contention and prevent
deadlocks, although Galera can run active/active. Used in combination with
the httpchk option, this ensure only nodes that are in sync with their
peers are allowed to handle requests.

Except where otherwise noted, this document is licensed under Creative Commons Attribution 3.0 License. See all OpenStack Legal Documents.