完全性ライフサイクル¶
We define integrity life cycle as a deliberate process that provides assurance that we are always running the expected software with the expected configurations throughout the cloud. This process begins with secure bootstrapping and is maintained through configuration management and security monitoring. This chapter provides recommendations on how to approach the integrity life-cycle process.
セキュアブートストラップ¶
クラウド内のノード (コンピュート、ストレージ、ネットワーク、サービス、およびハイブリッドのノードを含む) には、自動プロビジョニングプロセスを使用すべきです。このプロセスにより、ノードが一貫して正しくプロビジョニングされます。また、セキュリティパッチの適用、アップグレード、バグ修正、その他の重要な変更が円滑に行われます。このプロセスにより、クラウド内において最高権限で実行される新規ソフトウェアがインストールされるので、正しいソフトウェアがインストールされることを検証することが重要となります。これには、ブートプロセスの最初期段階が含まれます。
There are a variety of technologies that enable verification of these early boot stages. These typically require hardware support such as the trusted platform module (TPM), Intel Trusted Execution Technology (TXT), dynamic root of trust measurement (DRTM), and Unified Extensible Firmware Interface (UEFI) secure boot. In this book, we will refer to all of these collectively as secure boot technologies. We recommend using secure boot, while acknowledging that many of the pieces necessary to deploy this require advanced technical skills in order to customize the tools for each environment. Utilizing secure boot will require deeper integration and customization than many of the other recommendations in this guide. TPM technology, while common in most business class laptops and desktops for several years, and is now becoming available in servers together with supporting BIOS. Proper planning is essential to a successful secure boot deployment.
セキュアブートのデプロイに関する完全なチュートリアルは、本書の範囲外なので、その代わりとして、標準的なノードプロビジョニングプロセスにセキュアブートテクノロジーを統合する方法の枠組みを提供します。クラウドアーキテクトが更に詳しい情報を確認するには、関連する仕様およびソフトウェア設定のマニュアルを参照することをお勧めします。
ノードのプロビジョニング¶
ノードは、プロビジョニングに Preboot eXecution Environment (PXE) を使用すべきです。これにより、ノードの再デプロイに必要な作業が大幅に軽減されます。標準的なプロセスでは、ノードがサーバーからさまざまなブート段階 (実行するソフトウェアが徐々に複雑化) を受信する必要があります。
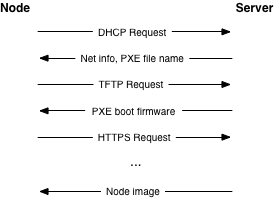
We recommend using a separate, isolated network within the management security domain for provisioning. This network will handle all PXE traffic, along with the subsequent boot stage downloads depicted above. Note that the node boot process begins with two insecure operations: DHCP and TFTP. Then the boot process uses TLS to download the remaining information required to deploy the node. This may be an operating system installer, a basic install managed by Ansible or Puppet, or even a complete file system image that is written directly to disk.
PXE ブートプロセス中に TLS を活用するのは若干困難ですが、iPXE などの一般的な PXE ファームウェアプロジェクトは、この機能をサポートしています。通常、この作業には、サーバーの証明書を適切に検証するための許可済み TLS 証明書チェーンについての知識を活用した PXE ファームウェア構築が伴います。これにより、安全性の低いプレーンテキストのネットワーク操作数が制限されるので、攻撃者に対するセキュリティレベルが高くなります。.
検証済みブート¶
In general, there are two different strategies for verifying the boot process. Traditional secure boot will validate the code run at each step in the process, and stop the boot if code is incorrect. Boot attestation will record which code is run at each step, and provide this information to another machine as proof that the boot process completed as expected. In both cases, the first step is to measure each piece of code before it is run. In this context, a measurement is effectively a SHA-1 hash of the code, taken before it is executed. The hash is stored in a platform configuration register (PCR) in the TPM.
注釈
SHA-1 is used here because this is what the TPM chips support.
各 TPM には少なくとも 24 の PCR が含まれます。TCG Generic Server Specification ( v1.0、2005 年 3 月版) には、ブート時の完全性計測のための PCR の割り当てが定義されています。以下の表には、標準的な PCR 設定を記載しています。コンテキストには、その値がノードのハードウェア (ファームウェア) をベースに決定されるか、ノードにプロビジョニングされているソフトウェアをベースに決定されるかを示しています。一部の値は、ファームウェアのバージョンやディスクサイズ、その他の低レベルの情報によって影響を受けます。このため、設定管理の適切なプラクティスを整備し、デプロイするシステムが要望通りに設定されるようにしておくことが重要となります。
レジスター |
計測の対象 |
コンテキスト |
|---|---|---|
PCR-00 |
Core Root of Trust Measurement (CRTM)、 BIOS コード、ホストプラットフォームの拡張機能 |
ハードウェア |
PCR-01 |
ハードウェアプラットフォームの設定 |
ハードウェア |
PCR-02 |
オプションの ROM コード |
ハードウェア |
PCR-03 |
オプションの ROM 設定およびデータ |
ハードウェア |
PCR-04 |
Initial Program Loader (IPL) コード (例: マスターブートレコード) |
ソフトウェア |
PCR-05 |
IPL コードの設定およびデータ |
ソフトウェア |
PCR-06 |
状態遷移とウェイクイベント |
ソフトウェア |
PCR-07 |
ホストプラットフォームのメーカーによる制御 |
ソフトウェア |
PCR-08 |
プラットフォーム固有、多くの場合はカーネル、カーネル拡張機能、ドライバー |
ソフトウェア |
PCR-09 |
プラットフォーム固有、多くの場合は Initramfs |
ソフトウェア |
PCR-10 から PCR-23 |
プラットフォーム固有 |
ソフトウェア |
Secure boot may be an option for building your cloud, but requires careful planning in terms of hardware selection. For example, ensure that you have a TPM and Intel TXT support. Then verify how the node hardware vendor populates the PCR values. For example, which values will be available for validation. Typically the PCR values listed under the software context in the table above are the ones that a cloud architect has direct control over. But even these may change as the software in the cloud is upgraded. Configuration management should be linked into the PCR policy engine to ensure that the validation is always up to date.
各メーカーは、サーバーの BIOS とファームウェアのコードを提供する必要があります。サーバー、ハイパーバイザー、オペレーティングシステムによって、事前設定される PCR 値の選択が異なります。実際のデプロイメントではほとんどの場合、既知の適切な量 (「黄金の計測値」) と対照して各 PCR を検証することは不可能です。単一のベンダー の製品ラインの場合でも、一定の PCR の計測プロセスに一貫性がない場合があることが、経験により実証されています。各サーバーに基準値を定め、 PCR 値の予期せぬ変化を監視することを推奨します。選択したハイパーバイザーソリューションによっては、TPM プロビジョニングおよび監視プロセスを支援する サードパーティー製のソフトウェアが提供されている可能性があります。
上記のノードデプロイメントの戦略を前提とすると、Initial Program Loader (IPL) コードは、PXE ファームウェアである可能性が最も高く、このため、セキュアブートまたはブートアテステーションプロセスで、BIOS、ファームウェア、PXE ファームウェア、カーネルイメージなど、すべての初期段階のブートコードを計測することができます。各ノードにこれらの正しいバージョンがインストールされていることを確認することにより、残りのノードソフトウェアスタックを構築する土台となる強固な基盤が提供されます。
選択した戦略に応じて、障害発生時にノードがブートに失敗するか、クラウド内の別のエンティティに障害を報告することができます。セキュアブートの場合には、ノードがブートに失敗し、管理セキュリティドメイン内のプロビジョニングサービスがこの問題を認識してイベントログを記録する必要があります。ブートアテステーションの場合には、障害検出時にはノードがすでに稼働している状態です。この場合、ネットワークアクセスを無効にすることによってノードの検疫を直ちに行った後に、イベントを解析して根本原因を特定するべきです。いずれの場合も、ポリシーにより、障害発生後の対処方法を指示する必要があります。クラウドが、特定の回数、ノードの再プロビジョニングを自動的に試みるようにしたり、問題を調査するようにクラウド管理者に直ちに通知するようにすることができます。この場合に適正となるポリシーは、デプロイメントと障害のモードによって異なります。
ノードのセキュリティ強化機能¶
At this point we know that the node has booted with the correct kernel and underlying components. The next step is to harden the operating system and it starts with a set of industry-accepted hardening controls. The following guides are good examples:
- Security Technical Implementation Guide (STIG)
The Defense Information Systems Agency (DISA) (part of the United States Department of Defense) publishes STIG content for various operating systems, applications, and hardware. The controls are published without any license attached.
- Center for Internet Security (CIS) Benchmarks
CIS regularly publishes security benchmarks as well as automated tools that apply those security controls automatically. These benchmarks are published under a Creative Commons license that has some limitations.
These security controls are best applied via automated methods. Automation ensures that the controls are applied the same way each time for each system and they also provide a quick method for auditing an existing system. There are multiple options for automation:
- OpenSCAP
OpenSCAP is an open source tool which takes SCAP content (XML files that describe security controls) and applies that content to various systems. Most of the available content available today is for Red Hat Enterprise Linux and CentOS, but the tools work on any Linux or Windows system.
- ansible-hardening
The ansible-hardening project provides an Ansible role that applies security controls to a wide array of Linux operating systems. It can also be used to audit an existing system. Each control is carefully reviewed to determine if it could cause harm to a production system. The controls are based on the Red Hat Enterprise Linux 7 STIG.
Fully hardening a system is a challenging process and it may require a substantial amount of changes to some systems. Some of these changes could impact production workloads. If a system cannot be fully hardened, the following two changes are highly recommended to increase security without large disruptions:
- Mandatory Access Control (MAC)
Mandatory access controls affect all users on the system, including root, and it is the kernel's job to review the activity against the current security policy. If the activity isn't within the allowed policy, it is blocked, even for the root user. Review the discussion on sVirt, SELinux, and AppArmor below for more details.
- Remove packages and stop services
Ensure that the system has the fewest number of packages installed and services running as possible. Removing unneeded packages makes patching easier and it reduces the number of items on the system which could lead to a breach. Stopping unneeded services shrinks the attack surface on the system and makes it more difficult to attack.
We also recommend the following additional steps for production nodes:
- Read-only file system
Use a read-only file system where possible. Ensure that writeable file systems do not permit execution. This can be handled with the
noexec,nosuid, andnodevmount options in/etc/fstab.- System validation
Finally, the node kernel should have a mechanism to validate that the rest of the node starts in a known good state. This provides the necessary link from the boot validation process to validating the entire system. The steps for doing this will be deployment specific. As an example, a kernel module could verify a hash over the blocks comprising the file system before mounting it using dm-verity.
ランタイムの検証¶
ノードが稼働したら、長時間にわたって良好な状態で稼働を継続するように確保する必要があります。大まかに言うと、これには設定管理とセキュリティ監視が含まれます。これらの各領域の目標は異なります。両方を確認することにより、システムが希望通りに稼働していることをより確実に保証します。設定管理については、管理のセクションおよび次のセキュリティ監視で説明します。
侵入検知システム¶
ホストベースの侵入検知ツールは、クラウド内部の検証の自動化にも役立ちます。ホストベースの侵入検知ツールにはさまざまな種類があります。オープンソースで自由に利用できるツールもあれば、商用のツールもあります。通常、これらのツールは、さまざまなソースからデータを分析し、ルールセットやトレーニングに基づいてセキュリティ警告を出します。標準的な機能には、ログ解析、ファイルの完全性チェック、ポリシー監視、ルートキット検出などがあります。また、より高度なツール (カスタムの場合が多い) を使用すると、インメモリープロセスイメージがオンディスクの実行可能ファイルと一致するかどうかを確認して、実行中のプロセスの実行状態を検証することができます。
セキュリティ監視ツールの出力の処理方法は、クラウドアーキテクトにとっての重要なポリシー決定の一つです。オプションは実質的に 2 つあります。第 1 のオプションは、問題を調査して修正措置を取るように、人間に警告を発する方法です。これは、クラウド管理者向けのログまたはイベントのフィードにセキュリティ警告を組み込むことによって可能となります。第 2 のオプションは、イベントのログ記録に加えて、クラウドが何らかの形の修復措置を自動的に実行するように設定する方法です。修復措置にはノードの再インストールから、マイナーなサービス設定の実行まで含めることができます。ただし、自動修復措置は、誤検知の可能性があるため、困難となる場合があります。
誤検知は、セキュリティ監視ツールが害のないイベントのセキュリティ警告を出した場合に発生します。セキュリティ警告ツールの性質上、時々誤検知が発生することは間違いありません。通常、クラウド管理者は、セキュリティ監視ツールを微調整して、誤検知を少なくすることができますが、これにより、全体的な検知率も同時に下がる場合があります。このような典型的トレードオフを理解し、クラウドにセキュリティ管理システムをセットアップする際には考慮に入れる必要があります。
ホストベースの侵入検知ツールの選択と設定はデプロイメントによって大幅に異なります。多様なホストベースの侵入検知/ファイル監視機能を実装する以下のオープンソースプロジェクトの検討から開始することをお勧めします。
ネットワーク侵入検知ツールは、ホストベースのツールを補完します。OpenStack には、特定のネットワーク IDS は組み込まれていませんが、OpenStack Networking は、Networking API を使用して異なるテクノロジーを有効にするプラグインメカニズムを提供しています。このプラグインのアーキテクチャーにより、テナントは API 拡張機能を開発して、ファイアウォール、侵入検知システム、仮想マシン間の VPN などの独自の高度なネットワークサービスを挿入/設定することができます。
Similar to host-based tools, the selection and configuration of a network-based intrusion detection tool is deployment specific. Snort is the leading open source networking intrusion detection tool, and a good starting place to learn more.
ネットワークおよびホストベースの侵入検知システムには、いくつかの重要なセキュリティ課題があります。
クラウドにネットワーク IDS の配置を検討することは重要です (例: ネットワーク境界や機密性の高いのネットワークに追加するなど)。 配置はネットワーク環境によって異なりますが、追加する場所によって IDS がサービスにもたらす可能性のある影響を確実に監視するようにしてください。通常 ネットワーク IDS は、TLS などの暗号化トラフィックを調査することはできませんが、ネットワーク上の異常な非暗号化トラフィックを特定するメリットを提供することができます。
一部のデプロイメントでは、ホストベースの IDS をセキュリティドメインブリッジ上の機密性の高いコンポーネントに追加する必要がある場合があります。ホストベースの IDS は、そのコンポーネント上の侵害された、あるいは許可されていないプロセスによる異常なアクティビティを検知することができます。IDS は管理ネットワーク上で警告およびログ情報を伝送すべきです。
サーバーのセキュリティ強化¶
Servers in the cloud, including undercloud and overcloud infrastructure, should implement hardening best practices. As OS and server hardening is common, applicable best practices including but not limited to logging, user account restrictions, and regular updates will not be covered here, but should be applied to all infrastructure.
ファイル完全性管理 (FIM)¶
File integrity management (FIM) is the method of ensuring that files such as sensitive system or application configuration files are not corrupted or changed to allow unauthorized access or malicious behavior. This can be done through a utility such as Samhain that will create a checksum hash of the specified resource and then validate that hash at regular intervals, or through a tool such as DMVerity that can take a hash of block devices and will validate those hashes as they are accessed by the system before they are presented to the user.
These should be put in place to monitor and report on changes to system,
hypervisor, and application configuration files such as
/etc/pam.d/system-auth and /etc/keystone/keystone.conf,
as well as kernel modules (such as virtio). Best practice is to use
the lsmod command to show what is regularly being loaded on a
system to help determine what should or should not be included in FIM checks.
