TripleO config-download User’s Guide: Deploying with Ansible¶
Introduction¶
This documentation details using config-download.
config-download is the feature that enables deploying the Overcloud software
configuration with Ansible in TripleO.
Summary¶
Since the Queens release, it has been possible to use Ansible to apply the overcloud configuration and with the Rocky release it became the default.
Ansible is used to replace the communication and transport of the software configuration deployment data between Heat and the Heat agent (os-collect-config) on the overcloud nodes.
Instead of os-collect-config running on each overcloud node and polling for
deployment data from Heat, the Ansible control node applies the configuration
by running ansible-playbook with an Ansible inventory file and a set of
playbooks and tasks.
The Ansible control node (the node running ansible-playbook) is the
undercloud by default.
config-download is the feature name that enables using Ansible in this
manner, and will often be used to refer to the method detailed in this
documentation.
Heat is still used to create the stack, then the ansible playbooks are saved to the filesystem in a git repository. These playbook are used to deploy the openstack services and configuration to the Overcloud nodes. The same parameter values and environment files are passed to Heat as they were previously. During the stack creation, Heat simply takes the user inputs from the templates and renders the required playbooks for the deployment.
The difference with config-download is that although Heat creates all the
deployment data necessary via SoftwareDeployment resources to perform the
overcloud installation and configuration, it does not apply any of the software
deployments. The data is only made available via the Heat API. Once the stack
is created, deployment data is downloaded from Heat and ansible playbooks are
generated.
Using the downloaded deployment data and ansible playbooks configuration of
the overcloud using ansible-playbook are completed.
This diagram details the overall sequence of how using config-download completes an overcloud deployment:
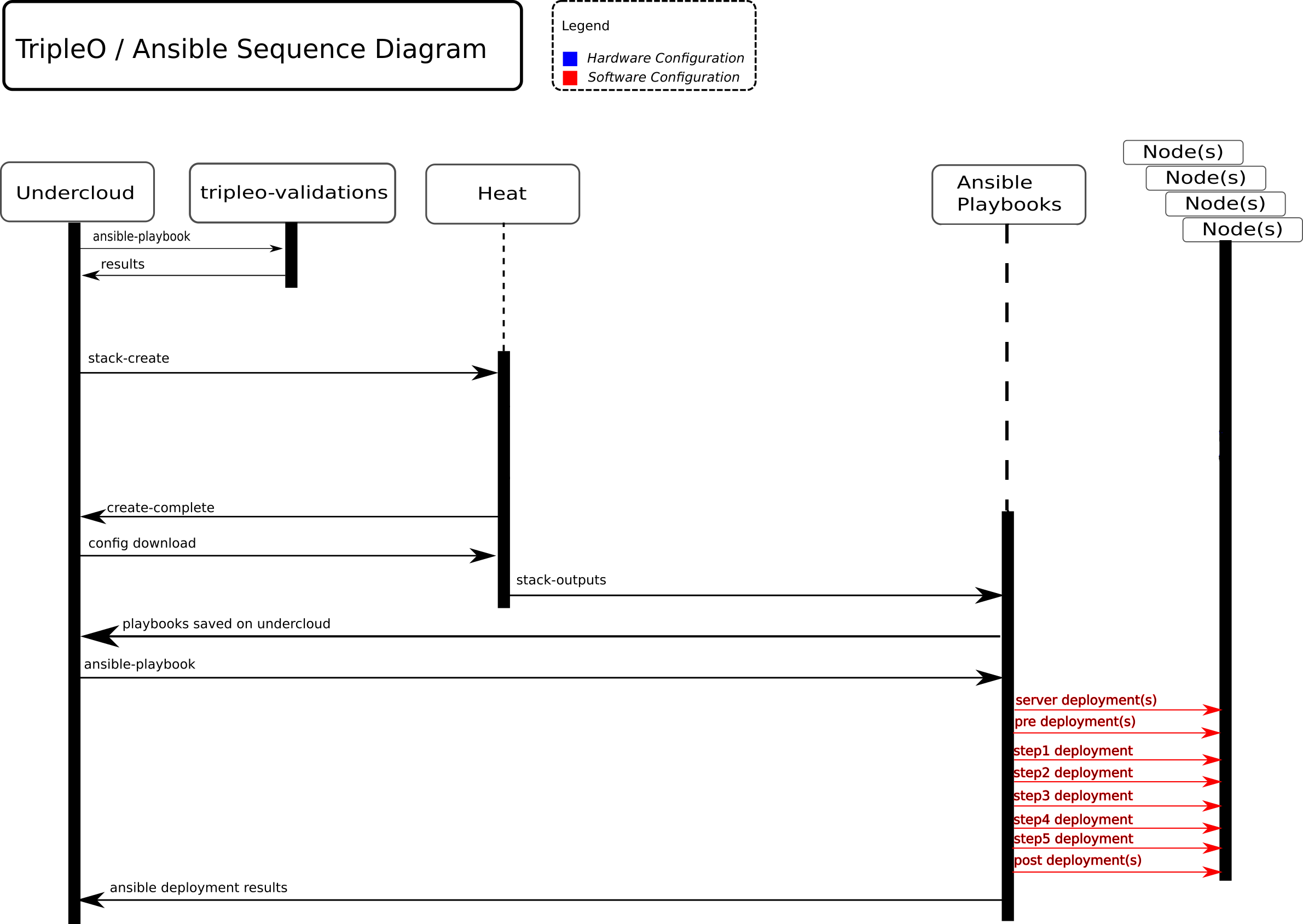
Deployment with config-download¶
Ansible and config-download are used by default when openstack
overcloud deploy (tripleoclient) is run. The command is backwards compatible
in terms of functionality, meaning that running openstack overcloud deploy
will still result in a full overcloud deployment.
The deployment is done through a series of steps in tripleoclient. All of the workflow steps are automated by tripleoclient. The workflow steps are summarized as:
Create deployment plan
Create Heat stack
Create software configuration within the Heat stack
Create tripleo-admin ssh user
Download the software configuration from Heat
Applying the downloaded software configuration to the overcloud nodes with
ansible-playbook.
The following steps are done to create the tripleo-admin user:
Runs a playbook to create
tripleo-adminon each node. Also, gives sudo permissions to the user, as well as creates and stores a new ssh keypair fortripleo-admin.
The values for these cli arguments must be the same for all nodes in the
overcloud deployment. overcloud-ssh-key should be the private key that
corresponds with the public key specified by the Heat parameter KeyName
when using Ironic deployed nodes.
Deployment Output¶
After the tripleo-admin user is created, ansible-playbook will be used to
configure the overcloud nodes.
The output from ansible-playbook will begin to appear in the console
and will be updated periodically as more tasks are applied.
When ansible is finished a play recap will be shown, and the usual overcloudrc details will then be displayed. The following is an example of the end of the output from a successful deployment:
PLAY RECAP ****************************************************************
compute-0 : ok=134 changed=48 unreachable=0 failed=0
openstack-0 : ok=164 changed=28 unreachable=0 failed=1
openstack-1 : ok=160 changed=28 unreachable=0 failed=0
openstack-2 : ok=160 changed=28 unreachable=0 failed=0
pacemaker-0 : ok=138 changed=30 unreachable=0 failed=0
pacemaker-1 : ok=138 changed=30 unreachable=0 failed=0
pacemaker-2 : ok=138 changed=30 unreachable=0 failed=0
undercloud : ok=2 changed=0 unreachable=0 failed=0
Overcloud configuration completed.
Overcloud Endpoint: http://192.168.24.8:5000/
Overcloud rc file: /home/stack/overcloudrc
Overcloud Deployed
When a failure happens, the deployment will stop and the error will be shown.
Review the PLAY RECAP which will show each host that is part of the
overcloud and the grouped count of each task status.
Deployment Status¶
Since Heat is no longer the source of authority on the status of the overcloud deployment, a new tripleoclient command is available to show the overcloud deployment status:
openstack overcloud status
The output will report the status of the deployment, taking into consideration the result of all the steps to do the full deployment. The following is an example of the output:
[stack@undercloud ]$ openstack overcloud status
+------------+-------------------+
| Stack Name | Deployment Status |
+------------+-------------------+
| overcloud | DEPLOY_SUCCESS |
+------------+-------------------+
A different stack name can be specified with --stack:
[stack@undercloud ]$ openstack overcloud status --stack my-deployment
+---------------+-------------------+
| Stack Name | Deployment Status |
+-----------+-----------------------+
| my-deployment | DEPLOY_SUCCESS |
+---------------+-------------------+
The deployment status is stored in the YAML file, generated at
$HOME/overcloud-deploy/<stack>/<stack>-deployment_status.yaml in
the undercloud node.
Deployment Log¶
The ansible part of the deployment creates a log file that is saved on the
undercloud. The log file is available at $HOME/ansible.log.
Ansible configuration¶
When ansible-playbook runs, it will use a configuration file with the
following default values:
[defaults]
retry_files_enabled = False
log_path = <working directory>/ansible.log
forks = 25
[ssh_connection]
ssh_args = -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no -o ControlMaster=auto -o ControlPersist=60s
control_path_dir = <working directory>/ansible-ssh
Any of the above configuration options can be overridden, or any additional
ansible configuration used by passing the path to an ansible configuration file
with --override-ansible-cfg on the deployment command.
For example the following command will use the configuration options from
/home/stack/ansible.cfg. Any options specified in the override file will
take precedence over the defaults:
openstack overcloud deploy \
...
--override-ansible-cfg /home/stack/ansible.cfg
Ansible project directory¶
The workflow will create an Ansible project directory with the plan name under
$HOME/overcloud-deploy/<stack>/config-download. For the default plan name of overcloud the working
directory will be:
$HOME/overcloud-deploy/overcloud/config-download/overcloud
The project directory is where the downloaded software configuration from
Heat will be saved. It also includes other ansible-related files necessary to
run ansible-playbook to configure the overcloud.
The contents of the project directory include the following files:
- tripleo-ansible-inventory.yaml
Ansible inventory file containing hosts and vars for all the overcloud nodes.
- ansible.log
Log file from the last run of
ansible-playbook.- ansible.cfg
Config file used when running
ansible-playbook.- ansible-playbook-command.sh
Executable script that can be used to rerun
ansible-playbook.- ssh_private_key
Private ssh key used to ssh to the overcloud nodes.
Reproducing ansible-playbook¶
Once in the project directory created, simply run ansible-playbook-command.sh
to reproduce the deployment:
./ansible-playbook-command.sh
Any additional arguments passed to this script will be passed unchanged to the
ansible-playbook command:
./ansible-playbook-command.sh --check
Using this method it is possible to take advantage of various Ansible features,
such as check mode (--check), limiting hosts (--limit), or overriding
variables (-e).
Git repository¶
The ansible project directory is a git repository. Each time config-download downloads the software configuration data from Heat, the project directory will be checked for differences. A new commit will be created if there are any changes from the previous revision.
From within the ansible project directory, standard git commands can be used to
explore each revision. Commands such as git log, git show, and git
diff are useful ways to describe how each commit to the software
configuration differs from previous commits.
Applying earlier versions of configuration¶
Using commands such as git revert or git checkout, it is possible to
update the ansible project directory to an earlier version of the software
configuration.
It is possible to then apply this earlier version with ansible-playbook.
However, caution should be exercised as this could lead to a broken overcloud
deployment. Only well understood earlier versions should be attempted to be
applied.
Note
Data migration changes will never be undone by applying an earlier version of the software configuration with config-download. For example, database schema migrations that had already been applied would never be undone by only applying an earlier version of the configuration.
Software changes that were related to hardware changes in the overcloud (such as scaling up or down) would also not be completely undone by applying earlier versions of the software configuration.
Note
Reverting to earlier revisions of the project directory has no effect on the configuration stored in the Heat stack. A corresponding change should be made to the deployment templates, and the stack updated to make the changes permanent.
Manual config-download¶
Prior to running the ansible playbooks generated by config-download, it is necessary to ensure the baremetal nodes have already been provisioned. See the baremetal deployment guide first:
configure-nodes-before-deployment
The config-download steps can be skipped when running openstack overcloud deploy
by passing --stack-only. This will cause tripleoclient to only deploy the Heat
stack.
When running openstack overcloud deploy with the --stack-only option, this
will still download the ansible content to the default directory
$HOME/overcloud-deploy/overcloud/config-download. But it will stop before running
the ansible-playbook command.
This method is described in the following sections.
Run ansible-playbook¶
Once the baremetal nodes have been configured, and the configuration has been
downloaded during the --stack-only run of openstack overcloud deploy.
You can then run ansible-playbook manually to configure the overcloud nodes:
ansible-playbook \
-i /home/stack/config-download/overcloud/tripleo-ansible-inventory.yaml \
--private-key /path/private/ssh/key \
--become \
config-download/deploy_steps_playbook.yaml
Note
--become is required when running ansible-playbook.
All default ansible configuration values will be used when manually running
ansible-playbook in this manner. These values can be customized through
ansible configuration.
The following minimum configuration is recommended:
[defaults]
log_path = ansible.log
forks = 25
timeout = 30
[ssh_connection]
ssh_args = -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no -o ControlMaster=auto -o ControlPersist=30m
retries = 8
pipelining = True
Note
When running ansible-playbook manually, the overcloud status as returned
by openstack overcloud status won’t be automatically updated due to the
configuration being applied outside of the API.
See Deployment Status for setting the status manually.
Ansible project directory contents¶
This section details the structure of the config-download generated
Ansible project directory.
Playbooks¶
- deploy_steps_playbook.yaml
Initial deployment or template update (not minor update)
Further detailed in deploy_steps_playbook.yaml
- fast_forward_upgrade_playbook.yaml
Fast forward upgrades
- post_upgrade_steps_playbook.yaml
Post upgrade steps for major upgrade
- pre_upgrade_rolling_steps_playbook.yaml
Pre upgrade steps for major upgrade
- update_steps_playbook.yaml
Minor update steps
- upgrade_steps_playbook.yaml
Major upgrade steps
deploy_steps_playbook.yaml¶
deploy_steps_playbook.yaml is the playbook used for deployment and template
update. It applies all the software configuration necessary to deploy a full
overcloud based on the templates provided as input to the deployment command.
This section will summarize at high level the different ansible plays used
within this playbook. The play names shown here are the same names used within
the playbook and are what will be shown in the output when ansible-playbook is
run.
The ansible tags set on each play are also shown below.
- Gather facts from undercloud
Fact gathering for the undercloud node
tags: facts
- Gather facts from overcloud
Fact gathering for the overcloud nodes
tags: facts
- Load global variables
Loads all variables from l`global_vars.yaml`
tags: always
- Common roles for TripleO servers
Applies common ansible roles to all overcloud nodes. Includes
tripleo_bootstrapfor installing bootstrap packages andtripleo_ssh_known_hostsfor configuring ssh known hosts.tags: common_roles
- Overcloud deploy step tasks for step 0
Applies tasks from the
deploy_steps_taskstemplate interfacetags: overcloud, deploy_steps
- Server deployments
Applies server specific Heat deployments for configuration such as networking and hieradata. Includes
NetworkDeployment,<Role>Deployment,<Role>AllNodesDeployment, etc.tags: overcloud, pre_deploy_steps
- Host prep steps
Applies tasks from the
host_prep_stepstemplate interfacetags: overcloud, host_prep_steps
- External deployment step [1,2,3,4,5]
Applies tasks from the
external_deploy_steps_taskstemplate interface. These tasks are run against the undercloud node only.tags: external, external_deploy_steps
- Overcloud deploy step tasks for [1,2,3,4,5]
Applies tasks from the
deploy_steps_taskstemplate interfacetags: overcloud, deploy_steps
- Overcloud common deploy step tasks [1,2,3,4,5]
Applies the common tasks done at each step to include puppet host configuration,
container-puppet.py, andpaunchortripleo_container_manageAnsible role (container configuration).tags: overcloud, deploy_steps
- Server Post Deployments
Applies server specific Heat deployments for configuration done after the 5 step deployment process.
tags: overcloud, post_deploy_steps
- External deployment Post Deploy tasks
Applies tasks from the
external_post_deploy_steps_taskstemplate interface. These tasks are run against the undercloud node only.tags: external, external_deploy_steps
Task files¶
These task files include tasks specific to their intended function. The task files are automatically used by specific playbooks from the previous section.
boot_param_tasks.yaml
common_deploy_steps_tasks.yaml
docker_puppet_script.yaml
external_deploy_steps_tasks.yaml
external_post_deploy_steps_tasks.yaml
fast_forward_upgrade_bootstrap_role_tasks.yaml
fast_forward_upgrade_bootstrap_tasks.yaml
fast_forward_upgrade_post_role_tasks.yaml
fast_forward_upgrade_prep_role_tasks.yaml
fast_forward_upgrade_prep_tasks.yaml
fast_forward_upgrade_release_tasks.yaml
upgrade_steps_tasks.yaml
update_steps_tasks.yaml
pre_upgrade_rolling_steps_tasks.yaml
post_upgrade_steps_tasks.yaml
post_update_steps_tasks.yaml
Heat Role directories¶
Each Heat role from the roles data file used in the deployment (specified with
-r from the openstack overcloud deploy command), will have a
correspondingly named directory.
When using the default roles, these directories would be:
Controller
Compute
ObjectStorage
BlockStorage
CephStorage
A given role directory contains role specific task files and a subdirectory for each host for that role. For example, when using the default hostnames, the Controller role directory would contain the following host subdirectories:
overcloud-controller-0
overcloud-controller-1
overcloud-controller-2
Other files¶
Other files in the project directory are:
- ansible-playbook-command.sh
Script to reproduce ansible-playbook command
- tripleo-ansible-inventory.yaml
Ansible inventory file
- overcloud-config.tar.gz
Tarball of Ansible project directory
Running specific tasks¶
Running only specific tasks (or skipping certain tasks) can be done from within the ansible project directory.
Note
Running specific tasks is an advanced use case and only recommended for specific scenarios where the deployer is aware of the impact of skipping or only running certain tasks.
This can be useful during troubleshooting and debugging scenarios, but should be used with caution as it can result in an overcloud that is not fully configured.
Warning
All tasks that are part of the deployment need to be run, and in the order
specified. When skipping tasks with --tags, -skip-tags,
--start-at-task, the deployment could be left in an inoperable state.
The functionality to skip tasks or only run certain tasks is meant to aid in troubleshooting and iterating more quickly on failing deployments and updates.
All changes to the deployed cloud must still be applied through the Heat
templates and environment files passed to the openstack overcloud deploy
command. Doing so ensures that the deployed cloud is kept in sync with the
state of the templates and the state of the Heat stack.
Warning
When skipping tasks, the overcloud must be in the state expected by the task starting task. Meaning, the state of the overcloud should be the same as if all the skipped tasks had been applied. Otherwise, the result of the tasks that get executed will be undefined and could leave the cloud in an inoperable state.
Likewise, the deployed cloud may not be left in its fully configured state if tasks are skipped at the end of the deployment.
Complete the Manual config-download steps to create the ansible project
directory, or use the existing project directory at
$HOME/overcloud-deploy/<stack-name>/config-download/<stack-name>.
Server specific pre and post deployments¶
The list of server specific pre and post deployments run during the Server deployments and Server Post Deployments plays (see deploy_steps_playbook.yaml) are dependent upon what custom roles and templates are used with the deployment.
The list of these tasks are defined in an ansible group variable that applies to each server in the inventory group named after the Heat role. From the ansible project directory, the value can be seen within the group variable file named after the Heat role:
$ cat group_vars/Compute
Compute_pre_deployments:
- UpgradeInitDeployment
- HostsEntryDeployment
- DeployedServerBootstrapDeployment
- InstanceIdDeployment
- NetworkDeployment
- ComputeUpgradeInitDeployment
- ComputeDeployment
- ComputeHostsDeployment
- ComputeAllNodesDeployment
- ComputeAllNodesValidationDeployment
- ComputeHostPrepDeployment
- ComputeArtifactsDeploy
Compute_post_deployments: []
<Role>_pre_deployments is the list of pre deployments, and
<Role>_post_deployments is the list of post deployments.
To specify the specific task to run for each deployment, the value of the
variable can be defined on the command line when running ansible-playbook,
which will overwrite the value from the group variable file for that role.
For example:
ansible-playbook \
-e Compute_pre_deployments=NetworkDeployment \
--tags pre_deploy_steps
# other CLI arguments
Using the above example, only the task for the NetworkDeployment resource
would get applied since it would be the only value defined in
Compute_pre_deployments, and --tags pre_deploy_steps is also specified,
causing all other plays to get skipped.
Starting at a specific task¶
To start the deployment at a specific task, use the ansible-playbook CLI
argument --start-at-task. To see a list of task names for a given playbook,
--list-tasks can be used to list the task names.
Note
Some tasks that include the step variable or other ansible variables in
the task name do not work with --start-at-task due to a limitation in
ansible. For example the task with the name:
Start containers for step 1
won’t work with --start-at-task since the step number is in the name
(1).
When using --start-at-task, the tasks that gather facts and load global
variables for the playbook execution are skipped by default. Skipping those
tasks can cause unexpected errors in later tasks. To avoid errors, those tasks
can be forced to execute when using --start-at-task by including the
following options to the ansible-playbook command:
ansible-playbook \
<other options > \
-e gather_facts=true \
-e @global_vars.yaml
The global_vars.yaml variable file exists in the config-download directory
that was either generated manually or under $HOME/config-download.
Previewing changes¶
Changes can be previewed to see what will be changed before any changes are
applied to the overcloud. To preview changes, the stack update must be run with
the --stack-only cli argument:
openstack overcloud deploy \
--stack-only
# other CLI arguments
When ansible-playbook is run, use the --check CLI argument with
ansible-playbook to preview any changes. The extent to which changes can be
previewed is dependent on many factors such as the underlying tools in use
(puppet, docker, etc) and the support for ansible check mode in the given
ansible module.
The --diff option can also be used with --check to show the
differences that would result from changes.
See Ansible Check Mode (“Dry Run”) for more details.
