Introduction to Data processing¶
The Data processing service controller will be responsible for creating, maintaining, and destroying any instances created for its clusters. The controller will use the Networking service to establish network paths between itself and the cluster instances. It will also manage the deployment and life-cycle of user applications that are to be run on the clusters. The instances within a cluster contain the core of a framework’s processing engine and the Data processing service provides several options for creating and managing the connections to these instances.
Data processing resources (clusters, jobs, and data sources) are segregated by projects defined within the Identity service. These resources are shared within a project and it is important to understand the access needs of those who are using the service. Activities within projects (for example launching clusters, uploading jobs, etc.) can be restricted further through the use of role-based access controls.
In this chapter we discuss how to assess the needs of data processing users with respect to their applications, the data that they use, and their expected capabilities within a project. We will also demonstrate a number of hardening techniques for the service controller and its clusters, and provide examples of various controller configurations and user management approaches to ensure an adequate level of security and privacy.
Architecture¶
The following diagram presents a conceptual view of how the Data processing service fits into the greater OpenStack ecosystem.
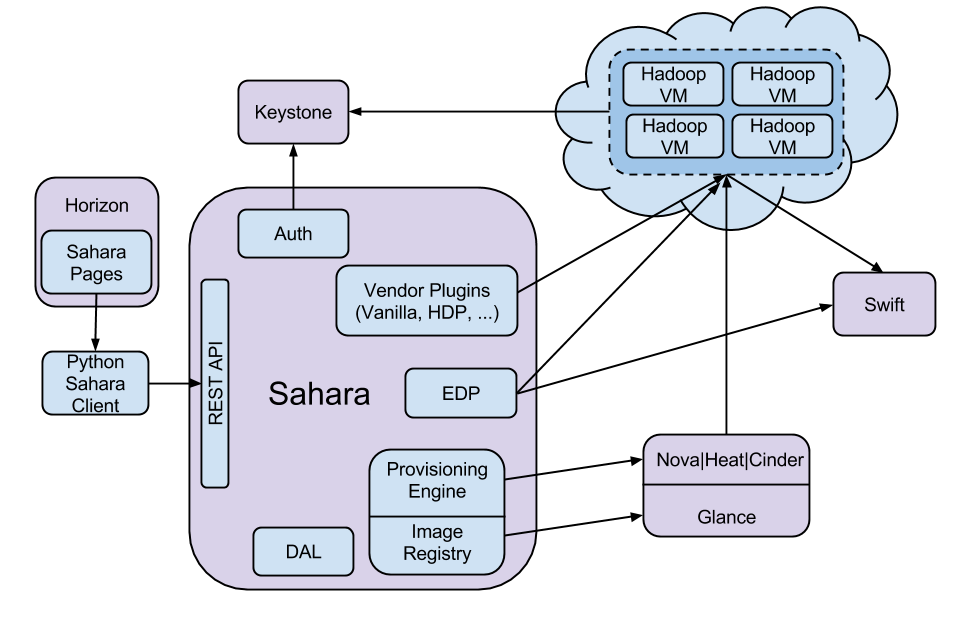
The Data processing service makes heavy use of the Compute, Orchestration, Image, and Block Storage services during the provisioning of clusters. It will also use one or more networks, created by the Networking service, provided during cluster creation for administrative access to the instances. While users are running framework applications the controller and the clusters will be accessing the Object Storage service. Given these service usages, we recommend following the instructions outlined in System documentation for cataloging all the components of an installation.
Technologies involved¶
The Data Processing service is responsible for the deployment and management of several applications. For a complete understanding of the security options provided we recommend that operators have a general familiarity with these applications. The list of highlighted technologies is broken into two sections: first, high priority applications that have a greater impact on security, and second, supporting applications with a lower impact.
Higher impact
Lower impact
These technologies comprise the core of the frameworks that are deployed with the Data processing service. In addition to these technologies, the service also includes bundled frameworks provided by third party vendors. These bundled frameworks are built using the same core pieces described above plus configurations and applications that the vendors include. For more information on the third party framework bundles please see the following links:
User access to resources¶
The resources (clusters, jobs, and data sources) of the Data processing service are shared within the scope of a project. Although a single controller installation may manage several sets of resources, these resources will each be scoped to a single project. Given this constraint we recommend that user membership in projects is monitored closely to maintain proper segregation of resources.
As the security requirements of organizations deploying this service will vary based on their specific needs, we recommend that operators focus on data privacy, cluster management, and end-user applications as a starting point for evaluating the needs of their users. These decisions will help guide the process of configuring user access to the service. For an expanded discussion on data privacy see Tenant data privacy.
The default assumption for a data processing installation is that users will have access to all functionality within their projects. In the event that more granular control is required the Data processing service provides a policy file (as described in Policies). These configurations will be highly dependent on the needs of the installing organization, and as such there is no general advice on their usage: see Role-based access control policies for details.
