[ English | Indonesia | 日本語 | Deutsch ]
Planung für die Bereitstellung und Bereitstellung von OpenStack¶
Die Entscheidungen, die Sie in Bezug auf Provisionierung und Bereitstellung treffen, wirken sich auf Ihre Wartung der Cloud aus. Ihr Konfigurationsmanagement wird sich im Laufe der Zeit weiterentwickeln können. Allerdings müssen mehr Überlegungen und Entwürfe angestellt werden, um im Vorfeld Entscheidungen über die Bereitstellung, Festplattenpartitionierung und Netzwerkkonfiguration treffen zu können.
A critical part of a cloud’s scalability is the amount of effort that it takes to run your cloud. To minimize the operational cost of running your cloud, set up and use an automated deployment and configuration infrastructure with a configuration management system, such as Puppet or Kolla Ansible. Combined, these systems greatly reduce manual effort and the chance for operator error.
This infrastructure includes systems to automatically install the operating system’s initial configuration and later coordinate the configuration of all services automatically and centrally, which reduces both manual effort and the chance for error. Examples include OpenStack-Ansible, Kolla Ansible and Puppet. You can even use OpenStack to deploy OpenStack, named TripleO (OpenStack On OpenStack).
Automatisierte Bereitstellung¶
Ein automatisiertes Bereitstellungssystem installiert und konfiguriert Betriebssysteme auf neuen Servern, ohne Eingriffe, nach dem absoluten Minimum an manueller Arbeit, einschließlich physischem Racking, MAC-zu-IP-Zuweisung und Stromkonfiguration. Typischerweise basieren Lösungen auf Wrappern um PXE-Boot- und TFTP-Server für die Installation des Basis-Betriebssystems und die Übergabe an ein automatisiertes Konfigurationsmanagementsystem.
Sowohl Ubuntu als auch Red Hat Enterprise Linux enthalten Mechanismen zur Konfiguration des Betriebssystems, einschließlich Preseed und Kickstart, die Sie nach einem Netzwerkstart verwenden können. Typischerweise werden diese verwendet, um ein automatisiertes Konfigurationssystem zu starten. Alternativ können Sie auch einen abbildbasierten Ansatz für die Bereitstellung des Betriebssystems verwenden, z.B. den Systemimager. Sie können beide Ansätze mit einer virtualisierten Infrastruktur verwenden, z. B. wenn Sie VMs ausführen, um Ihre Kontrolldienste und die physische Infrastruktur zu trennen.
Wenn Sie einen Bereitstellungsplan erstellen, konzentrieren Sie sich auf einige wichtige Bereiche, da sie nach der Bereitstellung nur sehr schwer zu ändern sind. In den nächsten beiden Abschnitten wird über die Konfigurationen für:
Festplattenpartitionierung und Festplattenarray-Setup für Skalierbarkeit
Netzwerkkonfiguration nur für das PXE-Booten
Festplattenpartitionierung und RAID¶
An der Basis eines jeden Betriebssystems befinden sich die Festplatten, auf denen das Betriebssystem (OS) installiert ist.
Sie müssen die folgenden Konfigurationen auf den Festplatten des Servers vornehmen:
Partitionierung, die eine größere Flexibilität für das Layout von Betriebssystem und Swap Space bietet, wie im Folgenden beschrieben.
Hinzufügen zu einem RAID-Array (RAID steht für redundantes Array unabhängiger Festplatten), basierend auf der Anzahl der verfügbaren Festplatten, so dass Sie Kapazität hinzufügen können, wenn Ihre Cloud wächst. Einige Optionen werden im Folgenden näher beschrieben.
Die einfachste Möglichkeit, mit dem Programm zu beginnen, ist die Verwendung einer Festplatte mit zwei Partitionen:
Dateisystem zum Speichern von Dateien und Verzeichnissen, in denen sich alle Daten befinden, einschließlich der Root-Partition, die das System startet und ausführt.
Swap Space, um Speicher für Prozesse freizugeben, als unabhängiger Bereich der physischen Festplatte, der nur für Swapping und nichts anderes verwendet wird.
RAID wird in diesem vereinfachten Ein-Laufwerk-Setup nicht verwendet, da Sie im Allgemeinen für Produktions-Clouds sicherstellen möchten, dass bei Ausfall einer Festplatte eine andere an ihre Stelle treten kann. Verwenden Sie stattdessen für die Produktion mehr als eine Festplatte. Die Anzahl der Festplatten bestimmt, welche Arten von RAID-Arrays erstellt werden sollen.
Wir empfehlen Ihnen, eine der folgenden Optionen für mehrere Festplatten zu wählen:
- Option 1
Partitionieren Sie alle Laufwerke horizontal auf die gleiche Weise, wie in Partitionierung von Laufwerken gezeigt.
Mit dieser Option können Sie verschiedenen RAID-Arrays verschiedene Partitionen zuweisen. Sie können die Partition 1 der Festplatte eins und zwei dem Partitions-Spiegel
/bootzuordnen. Sie können die Partition 2 aller Festplatten zum Root-Partitionsspiegel machen. Sie können die Partition 3 aller Festplatten für einecinder-volumesLVM-Partition verwenden, die auf einem RAID 10-Array läuft.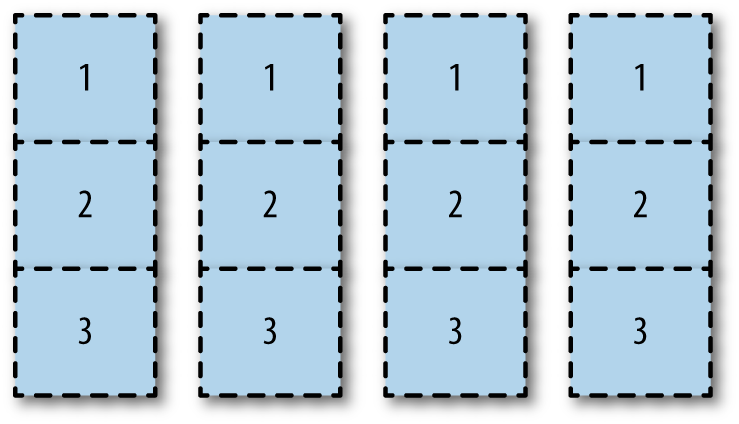
Partitionierung von Laufwerken¶
Während Sie in diesem Beispiel mit unbenutzten Partitionen enden können, wie z.B. Partition 1 in Laufwerk drei und vier, ermöglicht diese Option eine maximale Nutzung des Festplattenspeichers. Die I/O-Leistung kann ein Problem darstellen, da alle Festplatten für alle Aufgaben verwendet werden.
- Option 2
Fügen Sie alle Rohdatenträger zu einem großen RAID-Array hinzu, entweder hardware- oder softwarebasiert. Sie können dieses große Array mit den Bereichen boot, root, swap und LVM partitionieren. Diese Option ist einfach zu implementieren und verwendet alle Partitionen. Allerdings kann es bei der Festplatten-I/O zu Problemen kommen.
- Option 3
Weisen Sie ganze Festplatten bestimmten Partitionen zu. Sie können beispielsweise die Festplatte eins und zwei vollständig den Boot-, Root- und Swap-Partitionen unter einem RAID-1-Spiegel zuordnen. Ordnen Sie dann die Festplatten drei und vier vollständig der LVM-Partition zu, auch unter einem RAID-1-Spiegel. Festplatten-I/O sollte besser sein, da sich die I/O auf dedizierte Aufgaben konzentriert. Die LVM-Partition ist jedoch viel kleiner.
Tipp
You may find that you can automate the partitioning itself. For example, MIT uses Fully Automatic Installation (FAI) to do the initial PXE-based partition and then install using a combination of min/max and percentage-based partitioning.
Wie bei den meisten Architekturentscheidungen hängt die richtige Antwort von Ihrer Umgebung ab. Wenn Sie vorhandene Hardware verwenden, kennen Sie die Festplattendichte Ihrer Server und können einige Entscheidungen basierend auf den oben genannten Optionen treffen. Wenn Sie einen Beschaffungsprozess durchlaufen, helfen Ihnen die Anforderungen Ihres Benutzers auch bei der Bestimmung des Hardwarekaufs. Hier sind einige Beispiele aus einer privaten Cloud, die Webentwicklern benutzerdefinierte Umgebungen bei AT&T bietet. Dieses Beispiel stammt aus einem bestimmten Einsatz, so dass Ihre vorhandene Hardware oder Beschaffungsmöglichkeit davon abweichen kann. AT&T verwendet bei der Bereitstellung drei Arten von Hardware:
Hardware für Steuerungsknoten, die für alle zustandslosen OpenStack-API-Dienste verwendet wird. Etwa 32-64 GB Arbeitsspeicher, kleine angeschlossene Festplatte, ein Prozessor, unterschiedliche Anzahl von Kernen, wie z.B. 6-12.
Hardware für Compute-Knoten. Typischerweise 256 oder 144 GB Speicher, zwei Prozessoren, 24 Kerne. 4-6 TB direkt angeschlossener Speicher, typischerweise in einer RAID 5-Konfiguration.
Hardware für Speicherknoten. Typischerweise ist der Festplattenspeicher für die niedrigsten Kosten pro GB Speicherplatz optimiert, während die Effizienz des Racks erhalten bleibt.
Auch hier hängt die richtige Antwort von Ihrer Umgebung ab. Sie müssen Ihre Entscheidung auf der Grundlage der Kompromisse zwischen Raumnutzung, Einfachheit und I/O-Leistung treffen.
Netzwerkkonfiguration¶
Die Netzwerkkonfiguration ist ein sehr großes Thema, das sich über mehrere Bereiche dieses Buches erstreckt. Stellen Sie zunächst sicher, dass Ihre Server PXE booten und erfolgreich mit dem Bereitstellungsserver kommunizieren können.
Beispielsweise können Sie normalerweise keine NICs für VLANs beim PXE-Boot konfigurieren. Außerdem können Sie normalerweise nicht PXE-Boot mit gebundenen NICs durchführen. Wenn Sie in dieses Szenario geraten, sollten Sie einen einfachen 1 GB-Switch in einem privaten Netzwerk verwenden, in dem nur Ihre Cloud kommuniziert.
Automatisierte Konfiguration¶
Der Zweck des automatischen Konfigurationsmanagements ist es, die Konsistenz eines Systems ohne menschliches Zutun herzustellen und aufrechtzuerhalten. Sie möchten die Konsistenz Ihrer Implementierungen aufrechterhalten, damit Sie jedes Mal die gleiche Cloud haben, wiederholbar. Der richtige Einsatz von automatischen Konfigurationsmanagement-Tools stellt sicher, dass Komponenten der Cloud-Systeme in bestimmten Zuständen sind, und vereinfacht die Bereitstellung und Verbreitung von Konfigurationsänderungen.
These tools also make it possible to test and roll back changes, as they are fully repeatable. Conveniently, a large body of work has been done by the OpenStack community in this space. Puppet or Ansible, a configuration management tools, even provides official modules for OpenStack projects in an OpenStack infrastructure system known as Puppet OpenStack, OpenStack-Ansible and Kolla Ansible. Also, PackStack is a command-line utility for Red Hat Enterprise Linux and derivatives that uses Puppet modules to support rapid deployment of OpenStack on existing servers over an SSH connection.
Ein integraler Bestandteil eines Konfigurationsmanagementsystems ist das Element, das es steuert. Sie sollten alle Elemente, die Sie automatisch verwalten lassen möchten oder nicht, sorgfältig in Betracht ziehen. Beispielsweise möchten Sie möglicherweise keine Festplatten mit Benutzerdaten automatisch formatieren.
Fernverwaltung¶
Nach unserer Erfahrung sitzen die meisten Betreiber nicht direkt neben den Servern, auf denen die Cloud läuft, und viele besuchen nicht unbedingt gerne das Rechenzentrum. OpenStack sollte vollständig fernkonfigurierbar sein, aber manchmal läuft nicht alles nach Plan.
In diesem Fall ist es ein Segen, einen Out-of-Band-Zugriff auf Knoten mit OpenStack-Komponenten zu haben. Das IPMI-Protokoll ist hier der De-facto-Standard, und die Anschaffung von Hardware, die es unterstützt, wird dringend empfohlen, um das Ziel eines ausgeleuchteten Rechenzentrums zu erreichen.
Darüber hinaus sollten Sie auch die Fernsteuerung in Betracht ziehen. Während IPMI normalerweise den Stromversorgungszustand des Servers steuert, kann der Fernzugriff auf die PDU, an die der Server angeschlossen ist, wirklich nützlich sein, wenn alles verkeilt erscheint.
Weitere Überlegungen¶
Sie können Zeit sparen, indem Sie die Anwendungsfälle für die zu erstellende Cloud verstehen. Die Anwendungsfälle für OpenStack sind vielfältig. Einige beinhalten nur die Speicherung von Objekten, andere erfordern vorkonfigurierte Compute-Ressourcen, um die Einrichtung der Entwicklungsumgebung zu beschleunigen, und wieder andere benötigen eine schnelle Bereitstellung von Compute-Ressourcen, die bereits pro Mandant mit privaten Netzwerken gesichert sind. Ihre Benutzer benötigen möglicherweise hochredundante Server, um sicherzustellen, dass ihre Legacy-Anwendungen weiterhin ausgeführt werden. Vielleicht wäre es ein Ziel, diese Legacy-Anwendungen so zu gestalten, dass sie auf mehreren Instanzen in einer cloudy, fehlertoleranten Weise laufen, aber es nicht zu einem Ziel machen, diese Cluster im Laufe der Zeit zu erweitern. Ihre Benutzer können angeben, dass sie aufgrund der starken Nutzung des Windows-Servers Skalierungsüberlegungen benötigen.
Sie können Ressourcen sparen, indem Sie nach der besten Lösung für die Hardware suchen, die Sie bereits installiert haben. Möglicherweise haben Sie eine High-Density-Speicherhardware zur Verfügung. Sie können diese Server für OpenStack Object Storage formatieren und neu verwenden. All diese Überlegungen und Anregungen von Anwendern helfen Ihnen, Ihren Anwendungsfall und Ihren Bereitstellungsplan zu erstellen.
Tipp
Für weitere Informationen über die OpenStack-Bereitstellung untersuchen Sie die unterstützten und dokumentierten vorkonfigurierten, vorkonfigurierten Installationsprogramme für OpenStack von Unternehmen wie Canonical, Cisco, Cloudscaling, IBM, Metacloud, Mirantis, Rackspace, Red Hat, SUSE, und SwiftStack.
