[ English | Indonesia | 日本語 | Deutsch ]
Fehlerbehebung im Netzwerk¶
Die Fehlerbehebung im Netzwerk kann eine Herausforderung darstellen. Ein Netzwerkproblem kann an jeder Stelle in der Cloud zu Problemen führen. Die Verwendung einer logischen Fehlerbehebungsmethode kann helfen, das Problem zu mildern und zu isolieren, wo sich das Netzwerkproblem befindet. Dieses Kapitel soll Ihnen die Informationen geben, die Sie benötigen, um Probleme mit nova-network oder OpenStack Networking (neutron) mit Linux Bridge oder Open vSwitch zu identifizieren.
Verwenden von ip a zum Überprüfen von Schnittstellenzuständen¶
Verwenden Sie auf Compute-Knoten und Knoten, auf denen nova-network läuft, den folgenden Befehl, um Informationen über Schnittstellen anzuzeigen, einschließlich Informationen über IPs, VLANs und ob Ihre Schnittstellen aktiv sind:
# ip a
Wenn Sie auf eine Art von Netzwerkproblem stoßen, ist ein guter erster Schritt zur Fehlerbehebung, sicherzustellen, dass Ihre Schnittstellen aktiviert sind. Zum Beispiel:
$ ip a | grep state
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP
qlen 1000
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast
master br100 state UP qlen 1000
4: virbr0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN
5: br100: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP
Sie können den Zustand von virbr0 ignorieren, das ist eine Standardbrücke, die von libvirt erstellt und von OpenStack nicht verwendet wird.
Visualisierung des nova-Netzwerkverkehrs in der Cloud¶
Wenn Sie an einer Instanz angemeldet sind und einen externen Host, z.B. Google, pingen, nimmt das Ping-Paket den in Abbildung. Traffic-Route für Ping-Pakete angegebenen Weg.
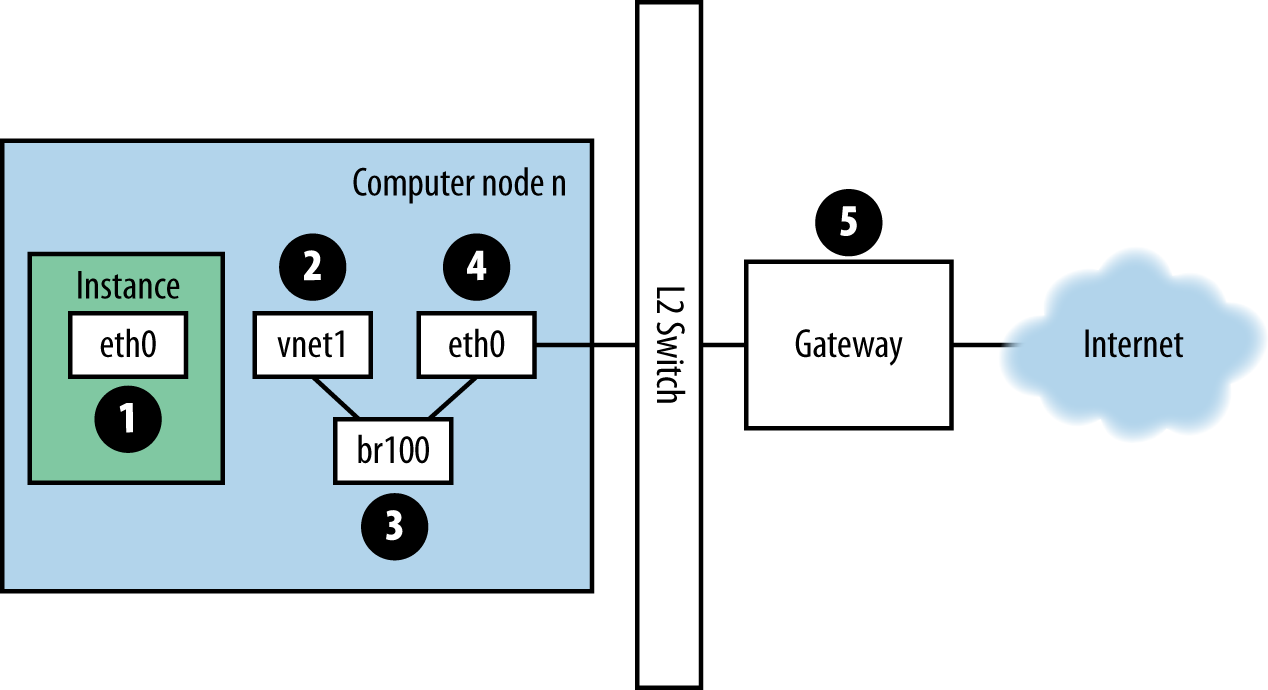
Abbildung. Traffic-Route für Ping-Pakete¶
Die Instanz erzeugt ein Paket und legt es auf der virtuellen Network Interface Card (NIC) innerhalb der Instanz ab, z.B.
eth0.Das Paket wird an das virtuelle NIC des Rechenhosts übertragen, z.B.
vnet1. Sie können herausfinden, welches vnet-NIC verwendet wird, indem Sie sich die Datei/etc/libvirt/qemu/instance-xxxxxxxxxxxx.xmlansehen.Vom vnet-NIC aus überträgt das Paket zu einer Brücke auf dem Compute-Knoten, wie z.B.
br100.Wenn Sie den FlatDHCPManager ausführen, befindet sich eine Bridge auf dem Compute-Knoten. Wenn Sie VlanManager ausführen, existiert für jedes VLAN eine Bridge.
Um zu sehen, welche Bridge das Paket verwenden wird, führen Sie den Befehl aus:
$ brctl show
Suchen Sie nach dem vnet NIC. Sie können auch auf
nova.confverweisen und nach der Optionflat_interface_bridgesuchen.Das Paket wird an das Hauptnetzwerk des Compute-Knotens übertragen. Sie können diesen NIC auch im brctl output sehen, oder Sie können ihn finden, indem Sie auf die Option
flat_interfaceinnova.confverweisen.Nachdem sich das Paket auf diesem NIC befindet, wird es an das Standardgateway des Compute-Knotens übertragen. Das Paket befindet sich nun höchstwahrscheinlich außerhalb Ihrer Kontrolle. Das Diagramm stellt ein externes Gateway dar. In der Standardkonfiguration mit Multi-Host ist der Compute Host jedoch das Gateway.
Umgekehrt die Richtung, um den Weg einer Ping-Antwort zu sehen. Aus diesem Pfad können Sie ersehen, dass ein einzelnes Paket über vier verschiedene NICs läuft. Wenn ein Problem mit einem dieser NICs auftritt, tritt ein Netzwerkproblem auf.
Visualisierung des Verkehrs des OpenStack Netzwerkdienstes in der Cloud¶
OpenStack Networking hat viel mehr Freiheitsgrade als nova-network aufgrund seines steckbaren Backends. Es kann mit Open-Source- oder herstellerspezifischen Plug-Ins konfiguriert werden, die softwaredefinierte Netzwerk-Hardware (SDN) oder Plug-Ins steuern, die native Linux-Einrichtungen auf Ihren Hosts verwenden, wie Open vSwitch oder Linux Bridge.
Das Netzwerkkapitel des OpenStack Administrator Guide zeigt eine Vielzahl von Netzwerkszenarien und deren Verbindungspfade. Der Zweck dieses Abschnitts ist es, Ihnen die Werkzeuge zur Verfügung zu stellen, um die verschiedenen beteiligten Komponenten zu beheben, egal wie sie in Ihrer Umgebung zusammengefügt sind.
Für dieses Beispiel verwenden wir das Open vSwitch (OVS) Backend. Andere Backend-Plug-Ins haben sehr unterschiedliche Fließwege. Laut der OpenStack User Survey vom April 2016 ist OVS der am häufigsten eingesetzte Netzwerktreiber. Wir werden jeden Schritt nacheinander beschreiben, mit Abbildung. Neutronnetzwerkpfade als Referenz.
Die Instanz erzeugt ein Paket und platziert es auf dem virtuellen NIC innerhalb der Instanz, z.B. eth0.
Das Paket wird zu einer Test Access Point (TAP)-Vorrichtung auf dem Rechenhost übertragen, wie z.B. tap690466bc-92. Sie können herausfinden, welches TAP verwendet wird, indem Sie sich die Datei
/etc/libvirt/qemu/instance-xxxxxxxxxxxx.xmlansehen.Der TAP-Gerätename wird aus den ersten 11 Zeichen der Port-ID (10 Hex-Ziffern plus einem enthaltenen ‚-‘) aufgebaut, so dass eine weitere Möglichkeit, den Gerätenamen zu finden, darin besteht, den Befehl neutron zu verwenden. Dies gibt eine Liste mit pipe-delimited zurück, deren erstes Element die Port-ID ist. Um beispielsweise die Port-ID der IP-Adresse 10.0.0.0.0.10 zu erhalten, führen Sie dies aus:
# openstack port list | grep 10.0.0.10 | cut -d \| -f 2 ff387e54-9e54-442b-94a3-aa4481764f1d
Aus den ersten 11 Zeichen können wir aus dieser Ausgabe einen Gerätenamen von tapff387e54-9e konstruieren.
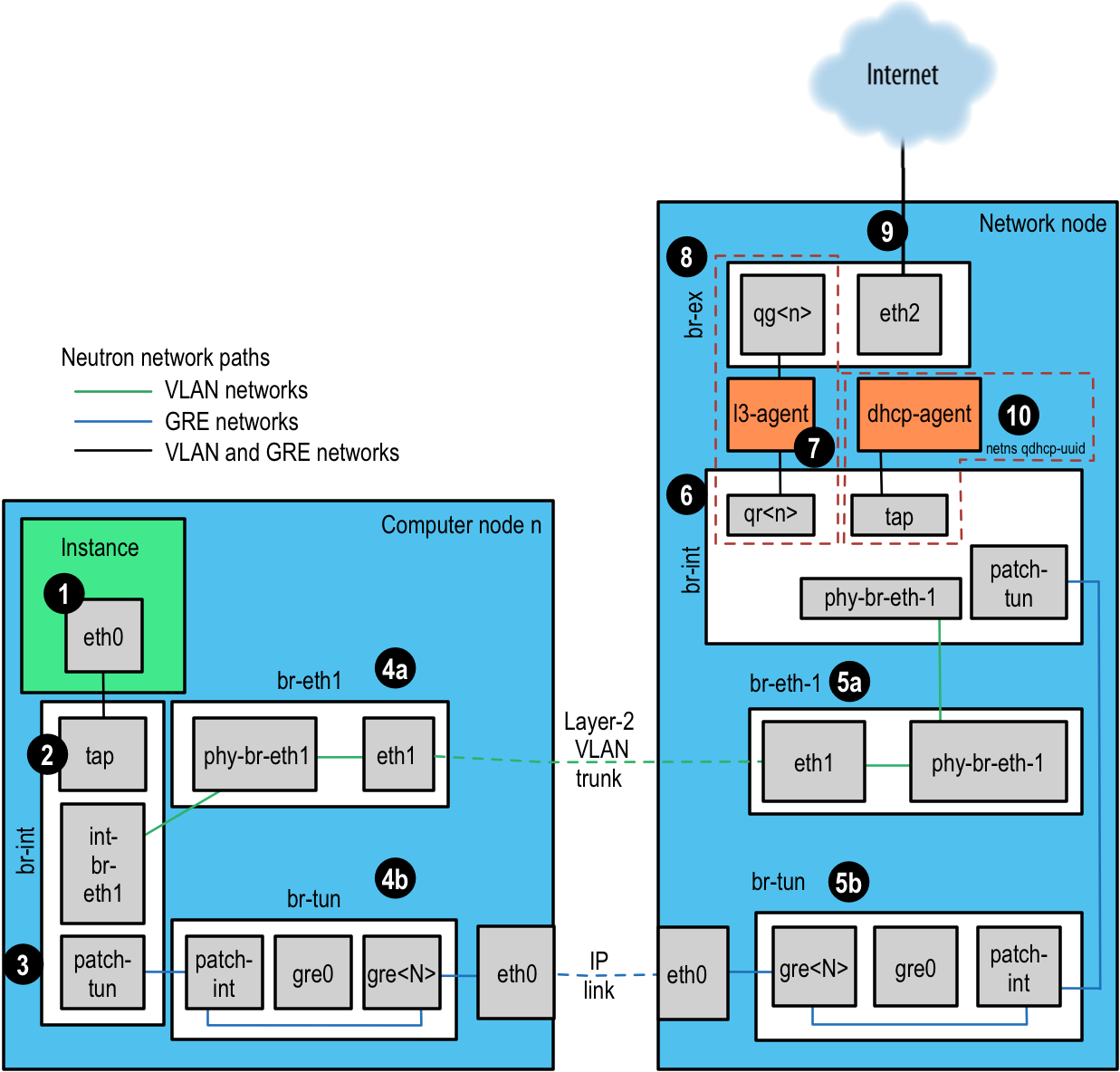
Abbildung. Neutronnetzwerkpfade¶
Das TAP-Gerät wird an die Integrationsbrücke
br-intangeschlossen. Diese Brücke verbindet alle Instanz-TAP-Geräte und alle anderen Brücken auf dem System. In diesem Beispiel haben wirint-br-eth1undPatch-Tun.int-br-eth1ist eine Hälfte eines Veth-Paares, das sich mit der Brückebr-eth1verbindet, die VLAN-Netzwerke verwaltet, die über die physikalische Ethernet-Vorrichtungeth1verbunden sind.Patch-Tunist ein interner Open vSwitch-Port, der mit der ``br-tun``Brücke für GRE-Netzwerke verbunden ist.Die TAP-Geräte und veth-Geräte sind normale Linux-Netzwerkgeräte und können mit den üblichen Tools wie ip und tcpdump überprüft werden. Offene interne vSwitch-Geräte, wie z.B.
patch-tun, sind nur innerhalb der Open vSwitch-Umgebung sichtbar. Wenn Sie versuchen, tcpdump -i patch-tun auszuführen, wird ein Fehler ausgelöst, der besagt, dass das Gerät nicht existiert.Es ist möglich, Pakete auf internen Schnittstellen zu beobachten, aber es braucht ein wenig Netzwerk-Gymnastik. Zuerst müssen Sie ein Dummy-Netzwerkgerät erstellen, das normale Linux-Tools sehen können. Dann müssen Sie es zu der Bridge hinzufügen, die das interne Interface enthält, an dem Sie den Verkehr mitlesen möchten. Schließlich müssen Sie Open vSwitch anweisen, den gesamten Datenverkehr vom oder zum internen Port auf diesen Dummy-Port zu spiegeln. Nach all dem können Sie dann tcpdump auf der Dummy-Schnittstelle ausführen und den Traffic auf dem internen Port sehen.
Um Pakete von der internen Patch-Tun-Schnittstelle auf der Integrationsbrücke zu erfassen, br-int:
Erstellen und öffnen Sie eine Dummy-Schnittstelle,
snooper0:# ip link add name snooper0 type dummy # ip link set dev snooper0 up
Gerät
snooper0zur Brückebr-inthinzufügen:# ovs-vsctl add-port br-int snooper0
Erstellt einen Spiegel von
Patch-TunnachSnooper0`(gibt UUID des Mirror-Ports zurück):# ovs-vsctl -- set Bridge br-int mirrors=@m -- --id=@snooper0 \ get Port snooper0 -- --id=@patch-tun get Port patch-tun \ -- --id=@m create Mirror name=mymirror select-dst-port=@patch-tun \ select-src-port=@patch-tun output-port=@snooper0 select_all=1
Gewinn. Sie können nun den Traffic auf
patch-tunsehen, indem Sie tcpdump -i snooper0 ausführen.Bereinigung durch Löschen aller Spiegel auf
br-intund Löschen der Dummy-Schnittstelle:# ovs-vsctl clear Bridge br-int mirrors # ovs-vsctl del-port br-int snooper0 # ip link delete dev snooper0
Auf der Integrationsbrücke werden Netzwerke über interne VLANs unterschieden, unabhängig davon, wie der Netzwerkdienst sie definiert. Dadurch können Instanzen auf demselben Host direkt kommunizieren, ohne den Rest des virtuellen oder physischen Netzwerks zu durchlaufen. Diese internen VLAN-IDs basieren auf der Reihenfolge, in der sie auf dem Knoten erstellt werden und können zwischen den Knoten variieren. Diese IDs stehen in keinerlei Zusammenhang mit den Segmentierungs-IDs, die in der Netzwerkdefinition und auf dem physischen Kabel verwendet werden.
VLAN-Tags werden zwischen dem in den Netzwerkeinstellungen definierten externen Tag und internen Tags an mehreren Stellen übersetzt. Auf dem
br-intwerden eingehende Pakete vomint-br-eth1von externen Tags in interne Tags umgewandelt. Andere Übersetzungen finden auch auf den anderen Brücken statt und werden in diesen Abschnitten behandelt.Um herauszufinden, welches interne VLAN-Tag für ein bestimmtes externes VLAN verwendet wird, verwenden Sie den Befehl ovs-ofctl
Suchen Sie das externe VLAN-Tag des Netzwerks, für das Sie sich interessieren. Dies ist die
Provider:segmentation_id, die vom Netzwerkdienst zurückgegeben wird:# neutron net-show --fields provider:segmentation_id <network name> +---------------------------+--------------------------------------+ | Field | Value | +---------------------------+--------------------------------------+ | provider:network_type | vlan | | provider:segmentation_id | 2113 | +---------------------------+--------------------------------------+
Grep für den
Provider:segmentation_id, 2113 in diesem Fall, in der Ausgabe von ovs-ofctl dump-flows br-int:# ovs-ofctl dump-flows br-int | grep vlan=2113 cookie=0x0, duration=173615.481s, table=0, n_packets=7676140, n_bytes=444818637, idle_age=0, hard_age=65534, priority=3, in_port=1,dl_vlan=2113 actions=mod_vlan_vid:7,NORMAL
Hier sehen Sie, dass Pakete, die auf Port ID 1 mit dem VLAN-Tag 2113 empfangen wurden, so modifiziert werden, dass sie den internen VLAN-Tag 7 haben. Wenn Sie etwas tiefer graben, können Sie bestätigen, dass Port 1 tatsächlich
int-br-eth1ist:# ovs-ofctl show br-int OFPT_FEATURES_REPLY (xid=0x2): dpid:000022bc45e1914b n_tables:254, n_buffers:256 capabilities: FLOW_STATS TABLE_STATS PORT_STATS QUEUE_STATS ARP_MATCH_IP actions: OUTPUT SET_VLAN_VID SET_VLAN_PCP STRIP_VLAN SET_DL_SRC SET_DL_DST SET_NW_SRC SET_NW_DST SET_NW_TOS SET_TP_SRC SET_TP_DST ENQUEUE 1(int-br-eth1): addr:c2:72:74:7f:86:08 config: 0 state: 0 current: 10GB-FD COPPER speed: 10000 Mbps now, 0 Mbps max 2(patch-tun): addr:fa:24:73:75:ad:cd config: 0 state: 0 speed: 0 Mbps now, 0 Mbps max 3(tap9be586e6-79): addr:fe:16:3e:e6:98:56 config: 0 state: 0 current: 10MB-FD COPPER speed: 10 Mbps now, 0 Mbps max LOCAL(br-int): addr:22:bc:45:e1:91:4b config: 0 state: 0 speed: 0 Mbps now, 0 Mbps max OFPT_GET_CONFIG_REPLY (xid=0x4): frags=normal miss_send_len=0
Der nächste Schritt hängt davon ab, ob das virtuelle Netzwerk für die Verwendung von 802.1q VLAN-Tags oder GRE konfiguriert ist:
VLAN-basierte Netzwerke verlassen die Integrationsbrücke über die veth-Schnittstelle
int-br-eth1und gelangen auf die Brückebr-eth1auf das andere Mitglied des Veth-Paaresphy-br-eth1. Pakete auf dieser Schnittstelle kommen mit internen VLAN-Tags an und werden in umgekehrter Reihenfolge des oben beschriebenen Prozesses in externe Tags übersetzt:# ovs-ofctl dump-flows br-eth1 | grep 2113 cookie=0x0, duration=184168.225s, table=0, n_packets=0, n_bytes=0, idle_age=65534, hard_age=65534, priority=4,in_port=1,dl_vlan=7 actions=mod_vlan_vid:2113,NORMAL
Pakete, die jetzt mit dem externen VLAN-Tag versehen sind, verlassen dann das physische Netzwerk über
eth1. Der Layer2-Switch, an den diese Schnittstelle angeschlossen ist, muss so konfiguriert sein, dass er den Datenverkehr mit der verwendeten VLAN-ID akzeptiert. Der nächste Hop für dieses Paket muss sich ebenfalls im gleichen Layer-2-Netzwerk befinden.GRE-basierte Netzwerke werden mit
patch-tunzur Tunnelbrückebr-tunan der Schnittstellepatch-intübergeben. Diese Brücke enthält auch einen Port für jeden GRE-Tunnel-Peer, also einen für jeden Compute-Knoten und Netzwerkknoten in Ihrem Netzwerk. Die Ports werden abgre-1sequentiell benannt.Die Anpassung von
gre-<n>Schnittstellen an Tunnel-Endpunkte ist im Zustand Open vSwitch möglich:# ovs-vsctl show | grep -A 3 -e Port\ \"gre- Port "gre-1" Interface "gre-1" type: gre options: {in_key=flow, local_ip="10.10.128.21", out_key=flow, remote_ip="10.10.128.16"}
In diesem Fall ist
gre-1ein Tunnel von IP 10.10.128.21, der einer lokalen Schnittstelle auf diesem Knoten entsprechen sollte, bis IP 10.10.128.16 auf der entfernten Seite.Diese Tunnel verwenden die regulären Routingtabellen auf dem Host, um das resultierende GRE-Paket zu routen, so dass es keine Anforderung gibt, dass sich die GRE-Endpunkte alle im gleichen Layer-2-Netzwerk befinden, im Gegensatz zur VLAN-Kapselung.
Alle Schnittstellen des
br-tunsind intern zu Open vSwitch. Um den Datenverkehr auf ihnen zu überwachen, müssen Sie einen Mirror-Port einrichten, wie vorstehend fürpatch-tunin derbr-intBrücke beschrieben.Alle Übersetzungen von GRE-Tunneln zu und von internen VLANs erfolgen auf dieser Brücke.
Um herauszufinden, welches interne VLAN-Tag für einen GRE-Tunnel verwendet wird, verwenden Sie den Befehl ovs-ofctl
Suchen Sie den
provider:segmentation_iddes Netzwerks, für das Sie sich interessieren. Dies ist das gleiche Feld, das für die VLAN-ID in VLAN-basierten Netzwerken verwendet wird:# neutron net-show --fields provider:segmentation_id <network name> +--------------------------+-------+ | Field | Value | +--------------------------+-------+ | provider:network_type | gre | | provider:segmentation_id | 3 | +--------------------------+-------+
Grep für 0x<
provider:segmentation_id>, 0x3 in diesem Fall, in der Ausgabe vonovs-ofctl dump-flows br-tun:# ovs-ofctl dump-flows br-tun|grep 0x3 cookie=0x0, duration=380575.724s, table=2, n_packets=1800, n_bytes=286104, priority=1,tun_id=0x3 actions=mod_vlan_vid:1,resubmit(,10) cookie=0x0, duration=715.529s, table=20, n_packets=5, n_bytes=830, hard_timeout=300,priority=1, vlan_tci=0x0001/0x0fff,dl_dst=fa:16:3e:a6:48:24 actions=load:0->NXM_OF_VLAN_TCI[], load:0x3->NXM_NX_TUN_ID[],output:53 cookie=0x0, duration=193729.242s, table=21, n_packets=58761, n_bytes=2618498, dl_vlan=1 actions=strip_vlan,set_tunnel:0x3, output:4,output:58,output:56,output:11,output:12,output:47, output:13,output:48,output:49,output:44,output:43,output:45, output:46,output:30,output:31,output:29,output:28,output:26, output:27,output:24,output:25,output:32,output:19,output:21, output:59,output:60,output:57,output:6,output:5,output:20, output:18,output:17,output:16,output:15,output:14,output:7, output:9,output:8,output:53,output:10,output:3,output:2, output:38,output:37,output:39,output:40,output:34,output:23, output:36,output:35,output:22,output:42,output:41,output:54, output:52,output:51,output:50,output:55,output:33
Hier sehen Sie drei Strömungen, die sich auf diesen GRE-Tunnel beziehen. Die erste ist die Übersetzung von eingehenden Paketen mit dieser Tunnel-ID in die interne VLAN-ID 1. Die zweite zeigt einen Unicastfluss zum Ausgabeport 53 für Pakete, die für die MAC-Adresse fa:16:3e:a6:48:24 bestimmt sind. Die dritte zeigt die Übersetzung von der internen VLAN-Darstellung in die GRE-Tunnel-ID, die an allen Ausgangsports geflutet wird. Weitere Details zu den Ablaufbeschreibungen finden Sie in der Man Page für
ovs-ofctl. Wie im vorherigen VLAN-Beispiel können numerische Port-IDs mit ihren benannten Darstellungen verglichen werden, indem man die Ausgabe von ovs-ofctl show br-tun` untersucht.
Das Paket wird dann auf dem Netzwerkknoten empfangen. Beachten Sie, dass jeglicher Traffic zum l3-Agenten oder dhcp-Agenten nur innerhalb seines Netzwerk-Namensraums sichtbar ist. Wenn Sie Schnittstellen außerhalb dieser Namensräume überwachen, auch solche, die den Netzwerkverkehr übertragen, werden nur Broadcast-Pakete wie Address Resolution Protocols (ARPs) angezeigt, aber Unicast-Verkehr zum Router oder zur DHCP-Adresse wird nicht angezeigt. Siehe Umgang mit Netzwerk-Namensräumen für Details darüber, wie Befehle innerhalb dieser Namensräume ausgeführt werden.
Alternativ ist es möglich, VLAN-basierte Netzwerke so zu konfigurieren, dass sie anstelle des hier gezeigten l3-Agenten externe Router verwenden, sofern sich der externe Router im selben VLAN befindet:
VLAN-basierte Netzwerke werden als markierte Pakete auf einer physikalischen Netzwerkschnittstelle empfangen, in diesem Beispiel
eth1. Genau wie auf dem Compute-Knoten ist diese Schnittstelle ein Element derbr-eth1Brücke.GRE-basierte Netzwerke werden an die Tunnelbrücke
br-tunübergeben, die sich genauso verhält wie die GRE-Schnittstellen auf dem Compute-Knoten.
Anschließend durchlaufen die Pakete von beiden Eingaben die Integrationsbrücke, wiederum genau wie auf dem Compute-Knoten.
Das Paket schafft es dann zum l3-Agenten. Dies ist eigentlich ein weiteres TAP-Gerät innerhalb des Netzwerk-Namensraums des Routers. Router-Namensräume werden in der Form
qrouter-<router-uuid>benannt. Wenn Sie den ip a innerhalb des Namensraums ausführen, wird der TAP-Gerätename qr-e6256f7d-31 in diesem Beispiel angezeigt:# ip netns exec qrouter-e521f9d0-a1bd-4ff4-bc81-78a60dd88fe5 ip a | grep state 10: qr-e6256f7d-31: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN 11: qg-35916e1f-36: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UNKNOWN qlen 500 28: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN
Das
qg-<n>`Interface im l3-agent Router Namensraum sendet das Paket an seinen nächsten Hop durch die Vorrichtungeth2auf der externen Brückebr-ex. Diese Brücke ist ähnlich aufgebaut wiebr-eth1und kann auf die gleiche Weise geprüft werden.Diese externe Brücke beinhaltet auch eine physikalische Netzwerkschnittstelle, in diesem Beispiel
eth2, die das Paket schließlich auf dem externen Netzwerk landet, das für einen externen Router oder ein externes Ziel bestimmt ist.DHCP-Agenten, die in OpenStack-Netzwerken ausgeführt werden, laufen in Namensräumen ähnlich den l3-Agenten. DHCP-Namensräume heißen
qdhcp-<uuid>und haben ein TAP-Gerät auf der Integrationsbrücke. Das Debuggen von DHCP-Problemen erfordert in der Regel das Arbeiten innerhalb dieses Netzwerk-Namensraums.
Finden eines Fehlers im Pfad¶
Verwenden Sie ping, um schnell herauszufinden, wo ein Fehler im Netzwerkpfad vorliegt. Überprüfen Sie in einer Instanz zunächst, ob Sie einen externen Host, wie z.B. google.com, pingen können. Wenn es geht, dann sollte es überhaupt kein Netzwerkproblem geben.
Wenn Sie dies nicht können, versuchen Sie, die IP-Adresse des Compute-Knotens, auf dem die Instanz gehostet wird, anzupingen. Wenn Sie diese IP pingen können, dann liegt das Problem irgendwo zwischen dem Compute-Knoten und dem Gateway dieses Compute-Knotens.
Wenn Sie die IP-Adresse des Compute-Knotens nicht auslesen können, liegt das Problem zwischen der Instanz und dem Compute-Knoten. Dazu gehört auch die Brücke, die das Haupt-NIC des Compute-Knotens mit dem Vnet-NIC der Instanz verbindet.
Ein letzter Test besteht darin, eine zweite Instanz zu starten und zu sehen, ob die beiden Instanzen sich gegenseitig pingen können. Wenn möglich, könnte das Problem mit der Firewall auf dem Compute-Knoten zusammenhängen.
tcpdump¶
Eine großartige, wenn auch sehr detaillierte Art der Fehlerbehebung bei Netzwerkproblemen ist die Verwendung von tcpdump. Wir empfehlen, tcpdump an mehreren Stellen entlang des Netzwerkpfades zu verwenden, um festzustellen, wo ein Problem auftreten könnte. Wenn Sie es vorziehen, mit einer GUI zu arbeiten, entweder live oder mit einem tcpdump Capture, schauen Sie sich Wireshark an.
Führen Sie beispielsweise den folgenden Befehl aus:
# tcpdump -i any -n -v 'icmp[icmptype] = icmp-echoreply or icmp[icmptype] = icmp-echo'
Führen Sie dies auf der Befehlszeile der folgenden Bereiche aus:
Ein externer Server außerhalb der Cloud
Compute Knoten
Eine Instanz, die auf diesem Compute-Knoten ausgeführt wird
In diesem Beispiel haben diese Standorte die folgenden IP-Adressen:
Instance
10.0.2.24
203.0.113.30
Compute Node
10.0.0.42
203.0.113.34
External Server
1.2.3.4
Als nächstes öffnen Sie eine neue Shell für die Instanz und pingen dann den externen Host, auf dem tcpdump läuft. Wenn der Netzwerkpfad zum externen Server und zurück voll funktionsfähig ist, sehen Sie so etwas wie das Folgende:
Auf dem externen Server:
12:51:42.020227 IP (tos 0x0, ttl 61, id 0, offset 0, flags [DF],
proto ICMP (1), length 84)
203.0.113.30 > 1.2.3.4: ICMP echo request, id 24895, seq 1, length 64
12:51:42.020255 IP (tos 0x0, ttl 64, id 8137, offset 0, flags [none],
proto ICMP (1), length 84)
1.2.3.4 > 203.0.113.30: ICMP echo reply, id 24895, seq 1,
length 64
Auf dem Compute-Knoten:
12:51:42.019519 IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF],
proto ICMP (1), length 84)
10.0.2.24 > 1.2.3.4: ICMP echo request, id 24895, seq 1, length 64
12:51:42.019519 IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF],
proto ICMP (1), length 84)
10.0.2.24 > 1.2.3.4: ICMP echo request, id 24895, seq 1, length 64
12:51:42.019545 IP (tos 0x0, ttl 63, id 0, offset 0, flags [DF],
proto ICMP (1), length 84)
203.0.113.30 > 1.2.3.4: ICMP echo request, id 24895, seq 1, length 64
12:51:42.019780 IP (tos 0x0, ttl 62, id 8137, offset 0, flags [none],
proto ICMP (1), length 84)
1.2.3.4 > 203.0.113.30: ICMP echo reply, id 24895, seq 1, length 64
12:51:42.019801 IP (tos 0x0, ttl 61, id 8137, offset 0, flags [none],
proto ICMP (1), length 84)
1.2.3.4 > 10.0.2.24: ICMP echo reply, id 24895, seq 1, length 64
12:51:42.019807 IP (tos 0x0, ttl 61, id 8137, offset 0, flags [none],
proto ICMP (1), length 84)
1.2.3.4 > 10.0.2.24: ICMP echo reply, id 24895, seq 1, length 64
Auf der Instanz:
12:51:42.020974 IP (tos 0x0, ttl 61, id 8137, offset 0, flags [none],
proto ICMP (1), length 84)
1.2.3.4 > 10.0.2.24: ICMP echo reply, id 24895, seq 1, length 64
Hier hat der externe Server die Ping-Anfrage empfangen und eine Ping-Antwort gesendet. Auf dem Compute-Knoten sehen Sie, dass sowohl die Ping- als auch die Ping-Antwort erfolgreich durchlaufen wurden. Möglicherweise sehen Sie auch doppelte Pakete auf dem Compute-Knoten, wie oben beschrieben, weil tcpdump das Paket sowohl auf der Bridge als auch auf der ausgehenden Schnittstelle erfasst hat.
iptables¶
Über nova-network oder neutron verwaltet OpenStack Compute automatisch iptables, einschließlich der Weiterleitung von Paketen zu und von Instanzen auf einem Compute-Knoten, der Weiterleitung von Floating IP-Traffic und der Verwaltung von Sicherheitsgruppenregeln. Zusätzlich zur Verwaltung der Regeln werden Kommentare (falls unterstützt) in die Regeln eingefügt, um den Zweck der Regel anzugeben.
Die folgenden Kommentare werden dem Regelsatz entsprechend hinzugefügt:
Führen Sie Quell-NAT für ausgehenden Datenverkehr durch.
Standard-Drop-Regel für unübertroffenen Traffic.
Leiten Sie den Datenverkehr von der VM-Schnittstelle an die Sicherheitsgruppen-Kette weiter.
Springen Sie zur VM-spezifischen Kette.
Leiten Sie eingehenden Datenverkehr von der VM an die Sicherheitsgruppen-Kette weiter.
Erlauben Sie Traffic von definierten IP/MAC-Paaren.
Drop-Traffic ohne eine IP/MAC-Zulassungsregel.
DHCP-Client-Verkehr zulassen.
DHCP-Spoofing durch VM verhindern.
Senden Sie unübertroffenen Traffic an die Fallback-Kette.
Lassen Sie Pakete fallen, die nicht mit einem Zustand verknüpft sind.
Leiten Sie Pakete, die einer bekannten Sitzung zugeordnet sind, an die RETURN-Kette weiter.
Erlauben Sie IPv6 ICMP-Datenverkehr, um RA-Pakete zuzulassen.
Führen Sie den folgenden Befehl aus, um die aktuelle iptables-Konfiguration anzuzeigen:
# iptables-save
Bemerkung
Wenn Sie die Konfiguration ändern, kehrt sie beim nächsten Neustart von nova-network oder neutron-server zurück. Sie müssen OpenStack verwenden, um iptables zu verwalten.
Netzwerkkonfiguration in der Datenbank für nova-network¶
Bei nova-network enthält die nova-Datenbanktabelle einige Tabellen mit Netzwerkinformationen:
fixed_ipsEnthält jede mögliche IP-Adresse für die Subnetze, die zu Compute hinzugefügt wurden. Diese Tabelle bezieht sich auf die Tabelle
instancesüber die Spalte fixed_ips.instance_uuuid`.floating_ipsEnthält jede freie IP-Adresse, die zu Compute hinzugefügt wurde. Diese Tabelle bezieht sich auf die Tabelle
fixed_ipsüber die Spaltefloating_ips.fixed_ip_id.InstanzenNicht ganz netzwerkspezifisch, aber es enthält Informationen über die Instanz, die das
fixed_ipund optionalfloating_ipverwendet.
Aus diesen Tabellen können Sie ersehen, dass eine Floating IP technisch gesehen nie direkt mit einer Instanz in Verbindung steht, sondern immer über eine feste IP laufen muss.
Manuelle Trennung einer Floating IP¶
Manchmal wird eine Instanz beendet, aber die Floating IP wurde nicht korrekt von dieser Instanz getrennt. Da sich die Datenbank in einem inkonsistenten Zustand befindet, funktionieren die üblichen Werkzeuge zur Trennung der IP nicht mehr. Um dies zu beheben, müssen Sie die Datenbank manuell aktualisieren.
Suchen Sie zunächst die UUID der betreffenden Instanz:
mysql> select uuid from instances where hostname = 'hostname';
Suchen Sie nun den festen IP-Eintrag für diese UUID:
mysql> select * from fixed_ips where instance_uuid = '<uuid>';
Sie können nun den zugehörigen Floating IP-Eintrag erhalten:
mysql> select * from floating_ips where fixed_ip_id = '<fixed_ip_id>';
Und schließlich können Sie die Floating IP dissoziieren:
mysql> update floating_ips set fixed_ip_id = NULL, host = NULL where
fixed_ip_id = '<fixed_ip_id>';
Optional können Sie die IP auch aus dem Pool des Benutzers entfernen:
mysql> update floating_ips set project_id = NULL where
fixed_ip_id = '<fixed_ip_id>';
Debuggen von DHCP-Problemen mit nova-network¶
Ein häufiges Netzwerkproblem ist, dass eine Instanz erfolgreich bootet, aber nicht erreichbar ist, weil sie keine IP-Adresse von dnsmasq erhalten hat, dem DHCP-Server, der vom Dienst nova-network gestartet wird.
Der einfachste Weg, um zu erkennen, dass dies das Problem mit Ihrer Instanz ist, ist ein Blick auf die Konsolenausgabe Ihrer Instanz. Wenn DHCP fehlgeschlagen ist, können Sie das Konsolenprotokoll abrufen:
$ openstack console log show <instance name or uuid>
Wenn Ihre Instanz keine IP über DHCP erhalten hat, sollten einige Meldungen in der Konsole erscheinen. Beispielsweise sehen Sie für das Cirros-Bild eine Ausgabe, die wie folgt aussieht:
udhcpc (v1.17.2) started
Sending discover...
Sending discover...
Sending discover...
No lease, forking to background
starting DHCP forEthernet interface eth0 [ [1;32mOK[0;39m ]
cloud-setup: checking http://169.254.169.254/2009-04-04/meta-data/instance-id
wget: can't connect to remote host (169.254.169.254): Network is
unreachable
Nachdem Sie festgestellt haben, dass die Instanz richtig gebootet hat, besteht die Aufgabe darin, herauszufinden, wo der Fehler liegt.
Ein DHCP-Problem kann durch einen fehlerhaften dnsmasq-Prozess verursacht werden. Zuerst debuggen, indem Sie Protokolle überprüfen und dann die dnsmasq-Prozesse nur für dieses Projekt (Mandant) neu starten. Im VLAN-Modus gibt es für jeden Mandanten einen dnsmasq-Prozess. Sobald Sie gezielte dnsmasq-Prozesse neu gestartet haben, ist der einfachste Weg, die Ursachen von dnsmasq auszuschließen, alle dnsmasq-Prozesse auf der Maschine zu beenden und das nova-network neu zu starten. Als letztes Mittel solltest du dies als root tun:
# killall dnsmasq
# restart nova-network
Bemerkung
Verwenden Sie openstack-nova-network auf RHEL/CentOS/Fedora, aber nova-network auf Ubuntu/Debian.
Einige Minuten nach dem Neustart von nova-network sollten Sie neue dnsmasq-Prozesse laufen sehen:
# ps aux | grep dnsmasq
nobody 3735 0.0 0.0 27540 1044 ? S 15:40 0:00 /usr/sbin/dnsmasq --strict-order
--bind-interfaces --conf-file=
--domain=novalocal --pid-file=/var/lib/nova/networks/nova-br100.pid
--listen-address=192.168.100.1 --except-interface=lo
--dhcp-range=set:'novanetwork',192.168.100.2,static,120s
--dhcp-lease-max=256
--dhcp-hostsfile=/var/lib/nova/networks/nova-br100.conf
--dhcp-script=/usr/bin/nova-dhcpbridge --leasefile-ro
root 3736 0.0 0.0 27512 444 ? S 15:40 0:00 /usr/sbin/dnsmasq --strict-order
--bind-interfaces --conf-file=
--domain=novalocal --pid-file=/var/lib/nova/networks/nova-br100.pid
--listen-address=192.168.100.1 --except-interface=lo
--dhcp-range=set:'novanetwork',192.168.100.2,static,120s
--dhcp-lease-max=256
--dhcp-hostsfile=/var/lib/nova/networks/nova-br100.conf
--dhcp-script=/usr/bin/nova-dhcpbridge --leasefile-ro
Wenn Ihre Instanzen immer noch nicht in der Lage sind, IP-Adressen zu erhalten, ist das nächste, was zu prüfen ist, ob dnsmasq die DHCP-Anforderungen von der Instanz sieht. Auf der Maschine, auf der der dnsmasq-Prozess läuft, der im Multi-Host-Modus der Compute-Host ist, finden Sie unter /var/log/syslog die Ausgabe von dnsmasq. Wenn dnsmasq die Anforderung richtig sieht und eine IP ausgibt, sieht die Ausgabe so aus:
Feb 27 22:01:36 mynode dnsmasq-dhcp[2438]: DHCPDISCOVER(br100) fa:16:3e:56:0b:6f
Feb 27 22:01:36 mynode dnsmasq-dhcp[2438]: DHCPOFFER(br100) 192.168.100.3
fa:16:3e:56:0b:6f
Feb 27 22:01:36 mynode dnsmasq-dhcp[2438]: DHCPREQUEST(br100) 192.168.100.3
fa:16:3e:56:0b:6f
Feb 27 22:01:36 mynode dnsmasq-dhcp[2438]: DHCPACK(br100) 192.168.100.3
fa:16:3e:56:0b:6f test
Wenn Sie den DHCPDISCOVER nicht sehen, besteht ein Problem damit, dass das Paket von der Instanz zu der Maschine gelangt, auf der dnsmasq läuft. Wenn Sie alle vorhergehenden Ausgaben sehen und Ihre Instanzen immer noch nicht in der Lage sind, IP-Adressen zu erhalten, dann kann das Paket von der Instanz zum Host mit dnsmasq gelangen, aber es ist nicht in der Lage, die Rückreise durchzuführen.
Möglicherweise wird auch eine solche Meldung angezeigt:
Feb 27 22:01:36 mynode dnsmasq-dhcp[25435]: DHCPDISCOVER(br100)
fa:16:3e:78:44:84 no address available
Dies kann ein dnsmasq- und/oder ``nova-network``bezogenes Problem sein. (Für das vorhergehende Beispiel bestand das Problem darin, dass dnsmasq keine weiteren IP-Adressen zum Verschenken hatte, weil in der OpenStack Compute-Datenbank keine festen IPs mehr verfügbar waren.)
Wenn es eine verdächtig aussehende dnsmasq-Protokollnachricht gibt, werfen Sie einen Blick auf die Befehlszeilenargumente für die dnsmasq-Prozesse, um festzustellen, ob sie korrekt aussehen:
$ ps aux | grep dnsmasq
Die Ausgabe sieht in etwa wie folgt aus:
108 1695 0.0 0.0 25972 1000 ? S Feb26 0:00 /usr/sbin/dnsmasq
-u libvirt-dnsmasq
--strict-order --bind-interfaces
--pid-file=/var/run/libvirt/network/default.pid --conf-file=
--except-interface lo --listen-address 192.168.122.1
--dhcp-range 192.168.122.2,192.168.122.254
--dhcp-leasefile=/var/lib/libvirt/dnsmasq/default.leases
--dhcp-lease-max=253 --dhcp-no-override
nobody 2438 0.0 0.0 27540 1096 ? S Feb26 0:00 /usr/sbin/dnsmasq
--strict-order --bind-interfaces --conf-file=
--domain=novalocal --pid-file=/var/lib/nova/networks/nova-br100.pid
--listen-address=192.168.100.1
--except-interface=lo
--dhcp-range=set:'novanetwork',192.168.100.2,static,120s
--dhcp-lease-max=256
--dhcp-hostsfile=/var/lib/nova/networks/nova-br100.conf
--dhcp-script=/usr/bin/nova-dhcpbridge --leasefile-ro
root 2439 0.0 0.0 27512 472 ? S Feb26 0:00 /usr/sbin/dnsmasq --strict-order
--bind-interfaces --conf-file=
--domain=novalocal --pid-file=/var/lib/nova/networks/nova-br100.pid
--listen-address=192.168.100.1
--except-interface=lo
--dhcp-range=set:'novanetwork',192.168.100.2,static,120s
--dhcp-lease-max=256
--dhcp-hostsfile=/var/lib/nova/networks/nova-br100.conf
--dhcp-script=/usr/bin/nova-dhcpbridge --leasefile-ro
Die Ausgabe zeigt drei verschiedene dnsmasq-Prozesse. Der dnsmasq-Prozess mit dem DHCP-Subnetzbereich von 192.168.122.0 gehört zu libvirt und kann ignoriert werden. Die beiden anderen dnsmasq-Prozesse gehören zum nova-network. Die beiden Prozesse sind tatsächlich miteinander verbunden - einer ist einfach der übergeordnete Prozess des anderen. Die Argumente der dnsmasq-Prozesse sollten den Details entsprechen, mit denen Sie nova-network konfiguriert haben.
Wenn das Problem nicht mit dnsmasq selbst zusammenhängt, verwenden Sie an dieser Stelle tcpdump auf den Schnittstellen, um festzustellen, wo die Pakete verloren gehen.
Der DHCP-Verkehr verwendet UDP. Der Client sendet von Port 68 an Port 67 auf dem Server. Versuchen Sie, eine neue Instanz zu booten und dann systematisch auf die NICs zu hören, bis Sie diejenige identifizieren, die den Traffic nicht sieht. Um tcpdump zu verwenden, um die Ports 67 und 68 auf br100 zu hören, würden Sie es tun:
# tcpdump -i br100 -n port 67 or port 68
Sie sollten Verträglichkeitsprüfungen an den Schnittstellen mit Befehlen wie ip a und brctl show durchführen, um sicherzustellen, dass die Schnittstellen tatsächlich hochgefahren sind und so konfiguriert sind, wie Sie es denken.
Debuggen von DNS-Problemen¶
Wenn Sie in der Lage sind, sich mit SSH bei einer Instanz anzumelden, es aber sehr lange dauert (in der Größenordnung einer Minute), bis Sie eine Eingabeaufforderung erhalten, dann haben Sie möglicherweise ein DNS-Problem. Der Grund, warum ein DNS-Problem dieses Problem verursachen kann, ist, dass der SSH-Server eine Reverse-DNS-Suche nach der IP-Adresse durchführt, von der aus Sie eine Verbindung herstellen. Wenn das DNS-Lookup auf Ihren Instanzen nicht funktioniert, müssen Sie warten, bis der DNS-Reverse-Lookup-Timeout auftritt, damit der SSH-Anmeldeprozess abgeschlossen ist.
Wenn Sie DNS-Probleme debuggen, stellen Sie zunächst sicher, dass der Host, auf dem der dnsmasq-Prozess für diese Instanz läuft, in der Lage ist, diese korrekt zu lösen. Wenn der Host nicht auflösen kann, dann können es auch die Instanzen nicht.
Eine schnelle Möglichkeit, um zu überprüfen, ob DNS funktioniert, besteht darin, einen Hostnamen innerhalb Ihrer Instanz mit dem Befehl host aufzulösen. Wenn DNS funktioniert, sollten Sie es sehen:
$ host openstack.org
openstack.org has address 174.143.194.225
openstack.org mail is handled by 10 mx1.emailsrvr.com.
openstack.org mail is handled by 20 mx2.emailsrvr.com.
Wenn Sie das Cirros-Abbild ausführen, ist das Programm „host“ nicht installiert. In diesem Fall können Sie mit ping versuchen, über den Hostnamen auf eine Maschine zuzugreifen, um zu sehen, ob sie sich auflöst. Wenn DNS funktioniert, ist die erste Zeile von ping:
$ ping openstack.org
PING openstack.org (174.143.194.225): 56 data bytes
Wenn die Instanz den Hostnamen nicht auflöst, haben Sie ein DNS-Problem. Zum Beispiel:
$ ping openstack.org
ping: bad address 'openstack.org'
In einer OpenStack-Cloud fungiert der dnsmasq-Prozess neben dem DHCP-Server auch als DNS-Server für die Instanzen. Ein fehlerhafter dnsmasq-Prozess kann die Ursache für DNS-Probleme innerhalb der Instanz sein. Wie im vorherigen Abschnitt erwähnt, ist der einfachste Weg, einen fehlerhaften dnsmasq-Prozess auszuschließen, alle dnsmasq-Prozesse auf der Maschine zu beenden und Nova-Netzwerk neu zu starten. Beachten Sie jedoch, dass dieser Befehl alle Instanzen auf diesem Knoten betrifft, einschließlich Mandanten, die das Problem nicht gesehen haben. Als letztes Mittel, als root:
# killall dnsmasq
# restart nova-network
Nachdem die dnsmasq-Prozesse erneut gestartet wurden, überprüfen Sie, ob das DNS funktioniert.
Wenn der Neustart des dnsmasq-Prozesses das Problem nicht behebt, müssen Sie möglicherweise tcpdump verwenden, um sich die Pakete anzusehen und zu verfolgen, wo der Fehler liegt. Der DNS-Server lauscht am UDP-Port 53. Sie sollten die DNS-Anfrage auf der Bridge (z.B. br100) Ihres Compute-Knotens sehen. Nehmen wir an, Sie beginnen mit dem Hören mit tcpdump auf dem Compute-Knoten:
# tcpdump -i br100 -n -v udp port 53
tcpdump: listening on br100, link-type EN10MB (Ethernet), capture size 65535 bytes
Wenn Sie sich dann mit SSH in Ihre Instanz einloggen und ping openstack.org versuchen, sollten Sie so etwas wie:
16:36:18.807518 IP (tos 0x0, ttl 64, id 56057, offset 0, flags [DF],
proto UDP (17), length 59)
192.168.100.4.54244 > 192.168.100.1.53: 2+ A? openstack.org. (31)
16:36:18.808285 IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF],
proto UDP (17), length 75)
192.168.100.1.53 > 192.168.100.4.54244: 2 1/0/0 openstack.org. A
174.143.194.225 (47)
Fehlerbehebung Open vSwitch¶
Open vSwitch, wie in den vorherigen OpenStack Networking-Beispielen verwendet, ist ein vollwertiger mehrschichtiger virtueller Switch, der unter der Open-Source-Lizenz Apache 2.0 lizenziert ist. Die vollständige Dokumentation finden Sie auf der Website des Projekts. In der Praxis ist es angesichts der vorhergehenden Konfiguration am häufigsten der Fall, sicherzustellen, dass die erforderlichen Brücken (br-int, br-tun, br-tun` und br-ex) existieren und die richtigen Ports mit ihnen verbunden sind.
Der Open vSwitch-Treiber sollte und wird dies in der Regel automatisch verwalten, aber es ist nützlich zu wissen, wie man dies von Hand mit dem Befehl ovs-vsctl macht. Dieser Befehl hat viel mehr Unterbefehle, als wir hier verwenden werden; siehe man page oder verwenden Sie den Befehl ovs-vsctl --help für die vollständige Liste.
Um die Brücken auf einem System aufzulisten, verwenden Sie den Befehl :ovs-vsctl listt-br. Dieses Beispiel zeigt einen Compute-Knoten, der eine interne Brücke und eine Tunnelbrücke aufweist. VLAN-Netzwerke werden über die Netzwerkschnittstelle eth1` trunked:
# ovs-vsctl list-br
br-int
br-tun
eth1-br
Wenn wir von der physischen Schnittstelle nach innen arbeiten, können wir die Kette der Ports und Brücken sehen. Zuerst die Brücke eth1-br, die die physikalische Netzwerkschnittstelle eth1 und die virtuelle Schnittstelle phy-eth1-br enthält:
# ovs-vsctl list-ports eth1-br
eth1
phy-eth1-br
Als nächstes enthält die interne Brücke, br-int`, int-eth1-br`, die sich mit phy-eth1-br paart, um sich mit dem physikalischen Netzwerk zu verbinden, das in der vorherigen Brücke gezeigt wird, Patch-Tun`, das verwendet wird, um sich mit der GRE-Tunnelbrücke und den TAP-Geräten zu verbinden, die sich mit den derzeit auf dem System laufenden Instanzen verbinden:
# ovs-vsctl list-ports br-int
int-eth1-br
patch-tun
tap2d782834-d1
tap690466bc-92
tap8a864970-2d
Die Tunnelbrücke, br-tun`, enthält die patch-int Schnittstelle und gre-<N> Schnittstellen für jeden Peer, mit dem sie sich über GRE verbindet, eine für jeden Rechen- und Netzwerkknoten in Ihrem Cluster:
# ovs-vsctl list-ports br-tun
patch-int
gre-1
.
.
.
gre-<N>
Wenn einer dieser Links fehlt oder falsch ist, wird ein Konfigurationsfehler angezeigt. Brücken können mit ovs-vsctl add-br hinzugefügt werden, und Ports können Brücken mit ovs-vsctl add-port hinzugefügt werden. Während die manuelle Ausführung dieser Funktionen ein nützliches Debugging sein kann, ist es unerlässlich, dass manuelle Änderungen, die Sie beibehalten möchten, wieder in Ihre Konfigurationsdateien übernommen werden.
Umgang mit Netzwerk-Namensräumen¶
Linux-Netzwerk-Namensräume sind eine Kernelfunktion, die der Netzwerkdienst verwendet, um mehrere isolierte Layer-2-Netzwerke mit überlappenden IP-Adressbereichen zu unterstützen. Der Support kann deaktiviert sein, ist aber standardmäßig eingeschaltet. Wenn es in Ihrer Umgebung aktiviert ist, führen Ihre Netzwerkknoten ihre dhcp-Agenten und l3-Agenten in isolierten Namensräumen aus. Netzwerkschnittstellen und Datenverkehr auf diesen Schnittstellen sind im Standard-Namensraum nicht sichtbar.
Um zu sehen, ob Sie Namensräume verwenden, führen Sie ip netns aus:
# ip netns
qdhcp-e521f9d0-a1bd-4ff4-bc81-78a60dd88fe5
qdhcp-a4d00c60-f005-400e-a24c-1bf8b8308f98
qdhcp-fe178706-9942-4600-9224-b2ae7c61db71
qdhcp-0a1d0a27-cffa-4de3-92c5-9d3fd3f2e74d
qrouter-8a4ce760-ab55-4f2f-8ec5-a2e858ce0d39
L3-Agenten-Router-Namensräume heißen qrouter-<router_uuid>, und dhcp-Agenten-Namensräume heißen qdhcp-<net_uuid>. Diese Ausgabe zeigt einen Netzwerkknoten mit vier Netzwerken mit DHCP-Agenten, von denen eines auch einen l3-Agenten-Router betreibt. Es ist wichtig zu wissen, in welchem Netzwerk Sie arbeiten müssen. Eine Liste der vorhandenen Netzwerke und ihrer UUIDs erhalten Sie, indem Sie openstack network list mit administrativen Anmeldeinformationen ausführen.
Sobald Sie festgestellt haben, in welchem Namensraum Sie arbeiten müssen, können Sie jedes der zuvor genannten Debugging-Tools verwenden, indem Sie dem Befehl ip netns exec <namespace> voranstellen. Um beispielsweise zu sehen, welche Netzwerkschnittstellen im ersten oben zurückgegebenen qdhcp-Namensraum vorhanden sind, führen Sie dies aus:
# ip netns exec qdhcp-e521f9d0-a1bd-4ff4-bc81-78a60dd88fe5 ip a
10: tape6256f7d-31: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN
link/ether fa:16:3e:aa:f7:a1 brd ff:ff:ff:ff:ff:ff
inet 10.0.1.100/24 brd 10.0.1.255 scope global tape6256f7d-31
inet 169.254.169.254/16 brd 169.254.255.255 scope global tape6256f7d-31
inet6 fe80::f816:3eff:feaa:f7a1/64 scope link
valid_lft forever preferred_lft forever
28: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
Daraus ersehen Sie, dass der DHCP-Server in diesem Netzwerk das Gerät tape6256f7d-31 verwendet und eine IP-Adresse von 10.0.1.100 hat. Wenn Sie die Adresse 169.254.169.169.254 sehen, können Sie auch sehen, dass der dhcp-Agent einen Metadaten-Proxy-Dienst betreibt. Jeder der zuvor in diesem Kapitel erwähnten Befehle kann auf die gleiche Weise ausgeführt werden. Es ist auch möglich, eine Shell, wie z.B. bash, auszuführen und eine interaktive Sitzung innerhalb des Namensraums durchzuführen. Im letzteren Fall kehren Sie durch das Verlassen der Shell in den obersten Standard-Namensraum zurück.
Weisen Sie einem Projekt eine verlorene IPv4-Adresse wieder zu¶
Vergewissern Sie sich anhand von Administrator-Anmeldeinformationen, dass die verlorene IP-Adresse noch verfügbar ist:
# openstack server list --all-project | grep 'IP-ADDRESS'
Erstellen Sie einen Port:
$ openstack port create --network NETWORK_ID PORT_NAME
Aktualisieren Sie den neuen Port mit der IPv4-Adresse:
# openstack subnet list # neutron port-update PORT_NAME --request-format=json --fixed-ips \ type=dict list=true subnet_id=NETWORK_ID_IPv4_SUBNET_ID \ ip_address=IP_ADDRESS subnet_id=NETWORK_ID_IPv6_SUBNET_ID # openstack port show PORT-NAME
Werkzeuge zur automatisierten Neutron-Diagnose¶
easyOVS ist ein nützliches Werkzeug, wenn es darum geht, Ihre OpenvSwitch-Brücken und iptables auf Ihrer OpenStack-Plattform zu betreiben. Die virtuellen Ports werden automatisch mit den Informationen zu VM MAC/IP, VLAN-Tag und Namensraum sowie den iptables-Regeln für VMs verknüpft.
Don ist ein weiteres komfortables Netzwerkanalyse- und Diagnosesystem, das einen vollständig automatisierten Service zur Überprüfung und Diagnose der von OVS bereitgestellten Netzwerkfunktionalität bietet.
Zusätzlich können Sie unter neutron client weitere Optionen finden.
