[ English | Indonesia | 日本語 | Deutsch ]
ネットワークのトラブルシューティング¶
ネットワークのトラブルシューティングは難しい場合もあります。ネットワークの問題は、クラウドのいくつかの場所で問題となりえます。論理的な問題解決手順を用いることで、問題の緩和やネットワークの問題の正確な切り分けにつながります。この章は、nova-network 、Linux ブリッジや Open vSwitch を用いた OpenStack Networking (neutron) に関する何らかの問題を識別するために必要となる情報を提供することを目的とします。
「ip a」を使ってインタフェース状態をチェックする¶
コンピュートノードおよび nova-network を実行しているノードにおいて、以下のコマンドを使用して、IP、VLAN、起動状態などのインターフェースに関する情報を参照します。
# ip a
もしあなたがネットワークの問題に直面した場合、まず最初にするとよいのは、インターフェイスが UP になっているかを確認することです。例えば、
$ ip a | grep state
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP
qlen 1000
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast
master br100 state UP qlen 1000
4: virbr0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN
5: br100: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP
virbr0 の状態は無視することができます。なぜならそれは libvirt が作成するデフォルトのブリッジで、OpenStack からは使われないからです。
クラウド上の nova-network 通信の仮想化¶
インスタンスにログインして、外部ホスト (例えば Google) に ping する場合、ping パケットは 図: ping パケットの通信ルート に示されたルートを通ります。
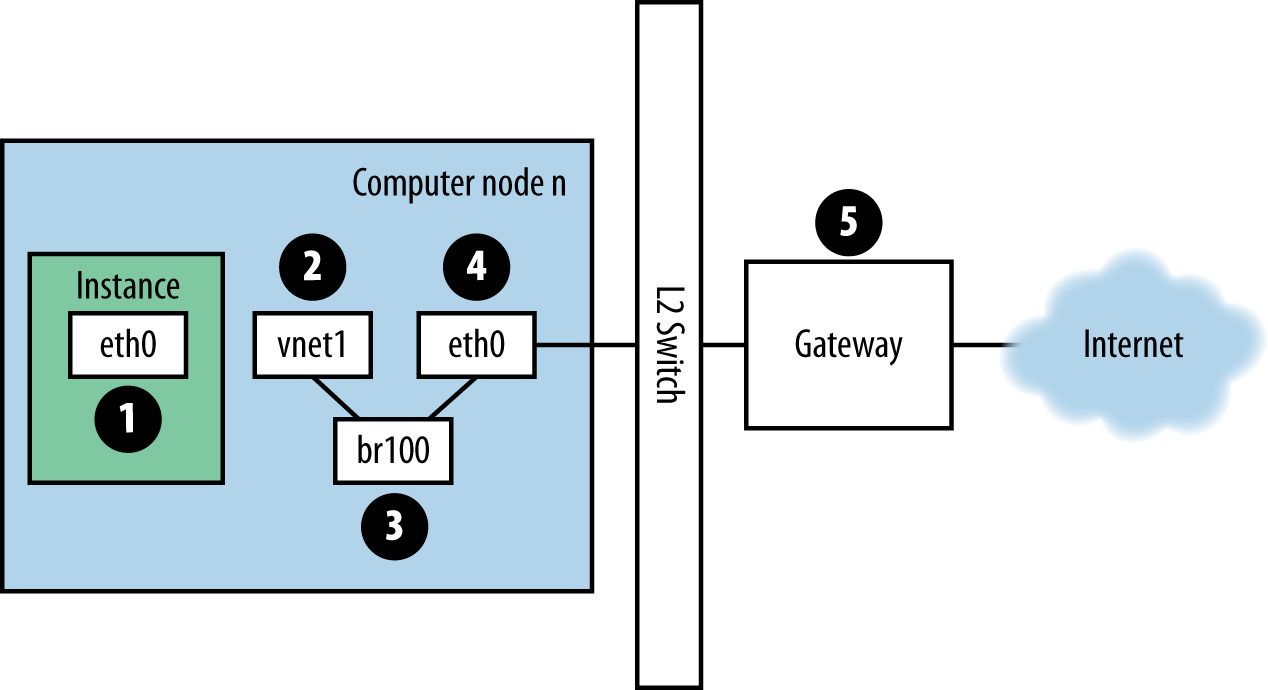
図: ping パケットの通信ルート¶
インスタンスはパケットを生成し、インスタンス内の仮想NIC、例えば
eth0にそれを渡します。そのパケットはコンピュートホストの仮想NIC、例えば
vnet1に転送されます。 vnet NIC の構成は、/etc/libvirt/qemu/instance-xxxxxxxx.xmlを見ることで把握できます。パケットは vnet NIC からコンピュートノードのブリッジ、例えば
br100に転送されます。もしFlatDHCPManagerを使っているのであれば、ブリッジはコンピュートノード上に一つです。VlanManagerであれば、VLANごとにブリッジが存在します。
下記コマンドを実行することで、パケットがどのブリッジを使うか確認できます。
$ brctl show
vnet NICを探してください。また、
nova.confのflat_interface_bridgeオプションも参考になります。パケットはコンピュートノードの物理NICに送られます。このNICは brctl コマンドの出力から、もしくは
nova.confのflat_interfaceオプションから確認できます。パケットはこのNICに送られた後、コンピュートノードのデフォルトゲートウェイに転送されます。パケットはこの時点で、おそらくあなたの管理範囲外でしょう。図には外部ゲートウェイを描いていますが、マルチホストのデフォルト構成では、コンピュートホストがゲートウェイです。
ping 応答のパスを確認するために、方向を反転させます。この経路説明によって、あなたはパケットが4つの異なるNICの間を行き来していることがわかったでしょう。これらのどのNICに問題が発生しても、ネットワークの問題となるでしょう。
クラウド上の OpenStack Networking サービス通信の仮想化¶
OpenStack Networking は、バックエンドをプラグインできるので、 nova-network よりも自由度が大きいです。SDN ハードウェアを制御するオープンソースやベンダー製品のプラグイン、ホストで動作する Open vSwitch や Linux Bridge などの Linux ネイティブの機能を使用するプラグインを用いて設定できます。
OpenStack Administrator Guide のネットワークの章に、さまざまな種類のネットワークのシナリオや接続パスがあります。このセクションの目的は、どのようにお使いの環境に一緒に関わっているかによらず、さまざまなコンポーネントをトラブルシューティングするためのツールを提供します。
この例のために、Open vSwitch (OVS) バックエンドを使用します。他のバックエンドプラグインは、まったく別のフロー経路になるでしょう。2016 年 4 月の OpenStack User Survey によると、 OVS は、最も一般的に配備されているネットワークドライバーです。 図: Neutron ネットワーク経路 を参照しながら、各手順を順番に説明していきます。
インスタンスはパケットを生成し、インスタンス内の仮想NIC、例えば eth0にそれを渡します。
そのパケットはコンピュートホストの Test Access Point (TAP)、例えば tap690466bc-92 に転送されます。TAP の構成は、
/etc/libvirt/qemu/instance-xxxxxxxx.xmlを見ることで把握できます。TAP デバイス名は、ポート ID の先頭 11 文字 (10 桁の16進数とハイフン) を使用して作られます。そのため、デバイス名を見つける別の手段として、
neutronコマンドを使用できます。これは、パイプ区切りの一覧を返し、最初の項目がポート ID です。例えば、次のように IP アドレス 10.0.0.10 に関連づけられているポート ID を取得します。# openstack port list | grep 10.0.0.10 | cut -d \| -f 2 ff387e54-9e54-442b-94a3-aa4481764f1d
この出力から最初の 11 文字をとり、デバイス名 tapff387e54-9e を作ることができます。
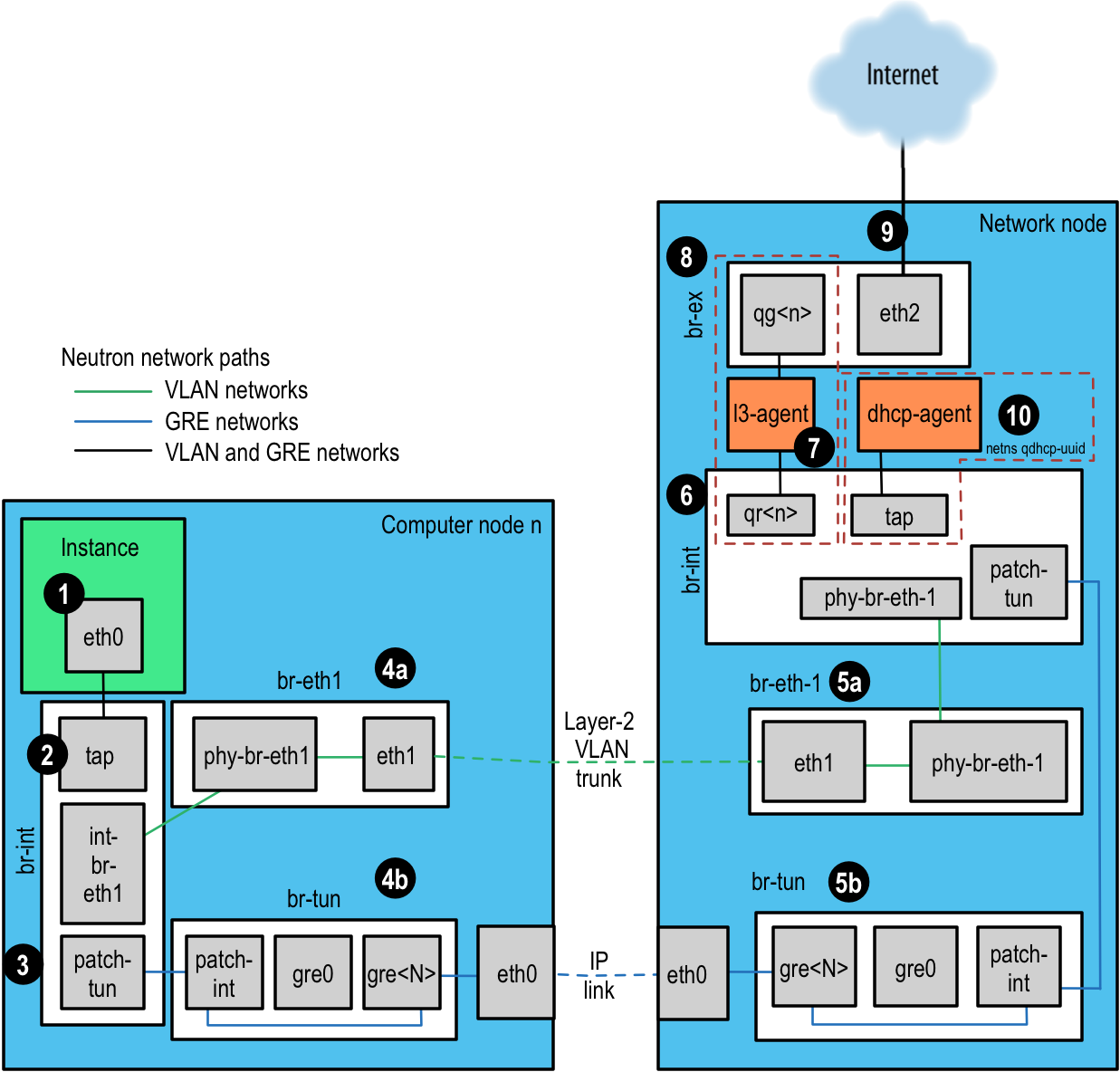
図: Neutron ネットワーク経路¶
TAP デバイスは統合ブリッジ
br-intに接続されます。このブリッジは、すべてのインスタンスの TAP デバイスや他のシステム上のブリッジを接続します。この例では、int-br-eth1とpatch-tunがあります。int-br-eth1は、ブリッジbr-eth1に接続している veth ペアの片側です。これは、物理イーサネットデバイスeth1経由でトランクされる VLAN ネットワークを処理します。patch-tunは、GRE ネットワークのbr-tunブリッジに接続している Open vSwitch 内部ポートです。TAP デバイスと veth デバイスは、通常の Linux ネットワークデバイスです。 ip や tcpdump などの通常のツールを用いて調査できるでしょう。
patch-tunのような Open vSwitch 内部デバイスは、Open vSwitch 環境の中だけで参照できます。 tcpdump -i patch-tun` を実行しようとした場合、デバイスが存在しないというエラーが発生するでしょう。内部インターフェースにおいてパケットを監視することもできますが、少しネットワークを操作する必要があります。まず、通常の Linux ツールが参照できるダミーネットワークデバイスを作成する必要があります。次に、監視したい内部インターフェースを含むブリッジにそれを追加する必要があります。最後に、内部ポートのすべての通信をこのダミーポートにミラーするよう Open vSwitch に通知する必要があります。これをすべて終えた後、ダミーインターフェースで tcpdump を実行して、内部ポートの通信を参照できます。
統合ブリッジ
br-intの内部インターフェースpatch-tunからのパケットをキャプチャーする方法。ダミーインターフェース
snooper0を作成して起動します。# ip link add name snooper0 type dummy # ip link set dev snooper0 up
snooper0デバイスをbr-intブリッジに追加します。# ovs-vsctl add-port br-int snooper0
patch-tunのミラーをsnooper0に作成します (ミラーポートの UUID を返します)。# ovs-vsctl -- set Bridge br-int mirrors=@m -- --id=@snooper0 \ get Port snooper0 -- --id=@patch-tun get Port patch-tun \ -- --id=@m create Mirror name=mymirror select-dst-port=@patch-tun \ select-src-port=@patch-tun output-port=@snooper0 select_all=1
これでうまくいきます。 tcpdump -i snooper0 を実行して、
patch-tunの通信を参照できます。br-intにあるすべてのミラーを解除して、ダミーインターフェースを削除することにより、クリーンアップします。# ovs-vsctl clear Bridge br-int mirrors # ovs-vsctl del-port br-int snooper0 # ip link delete dev snooper0
内部ブリッジにおいて、ネットワークサービスがどのように定義されているかによらず、ネットワークは内部 VLAN を使用して区別されます。これにより、同じホストにあるインスタンスが、仮想、物理、ネットワークを転送することなく直接通信できるようになります。これらの内部 VLAN ID は、ノードにおいて作成された順番に基づき、ノード間で異なる可能性があります。これらの ID は、ネットワーク定義および物理結線において使用されるセグメント ID にまったく関連しません。
VLAN タグは、ネットワーク設定において定義された外部タグといくつかの場所にある内部タグの間で変換されます。
br-intにおいて、int-br-eth1からの受信パケットは、外部タグから内部タグへと変換されます。他の変換が他のブリッジにおいても発生します。これらのセクションで議論されます。ovs-ofctl コマンドを使用することにより、外部 VLAN 向けに使用されている内部 VLAN タグを検索します。
興味のあるネットワークの外部 VLAN タグを見つけます。これは、ネットワークサービスにより返される
provider:segmentation_idです。# neutron net-show --fields provider:segmentation_id <network name> +---------------------------+--------------------------------------+ | Field | Value | +---------------------------+--------------------------------------+ | provider:network_type | vlan | | provider:segmentation_id | 2113 | +---------------------------+--------------------------------------+
この場合、 ovs-ofctl dump-flows br-int の出力で
provider:segmentation_idを、この場合は 2113 を grep します。# ovs-ofctl dump-flows br-int | grep vlan=2113 cookie=0x0, duration=173615.481s, table=0, n_packets=7676140, n_bytes=444818637, idle_age=0, hard_age=65534, priority=3, in_port=1,dl_vlan=2113 actions=mod_vlan_vid:7,NORMAL
これで VLAN タグ 2113 を持つポート ID 1 で受信したパケットを参照できます。これは変換され、内部 VLAN タグ 7 を持ちます。より深く掘り下げると、ポート 1 が実際に
int-br-eth1であることが確認できます。# ovs-ofctl show br-int OFPT_FEATURES_REPLY (xid=0x2): dpid:000022bc45e1914b n_tables:254, n_buffers:256 capabilities: FLOW_STATS TABLE_STATS PORT_STATS QUEUE_STATS ARP_MATCH_IP actions: OUTPUT SET_VLAN_VID SET_VLAN_PCP STRIP_VLAN SET_DL_SRC SET_DL_DST SET_NW_SRC SET_NW_DST SET_NW_TOS SET_TP_SRC SET_TP_DST ENQUEUE 1(int-br-eth1): addr:c2:72:74:7f:86:08 config: 0 state: 0 current: 10GB-FD COPPER speed: 10000 Mbps now, 0 Mbps max 2(patch-tun): addr:fa:24:73:75:ad:cd config: 0 state: 0 speed: 0 Mbps now, 0 Mbps max 3(tap9be586e6-79): addr:fe:16:3e:e6:98:56 config: 0 state: 0 current: 10MB-FD COPPER speed: 10 Mbps now, 0 Mbps max LOCAL(br-int): addr:22:bc:45:e1:91:4b config: 0 state: 0 speed: 0 Mbps now, 0 Mbps max OFPT_GET_CONFIG_REPLY (xid=0x4): frags=normal miss_send_len=0
次の手順は、仮想ネットワークが 802.1q VLAN タグや GRE を使用するよう設定しているかどうかに依存します。
VLAN ベースのネットワークは、仮想インターフェース
int-br-eth1経由で統合ブリッジを抜けて、仮想イーサネットペアphy-br-eth1の他のメンバーにあるブリッジbr-eth1に届きます。このインターフェースのパケットは、内部 VLAN タグとともに届き、上で説明したプロセスの逆順において外部タグに変換されます。# ovs-ofctl dump-flows br-eth1 | grep 2113 cookie=0x0, duration=184168.225s, table=0, n_packets=0, n_bytes=0, idle_age=65534, hard_age=65534, priority=4,in_port=1,dl_vlan=7 actions=mod_vlan_vid:2113,NORMAL
パケットは、いま外部 VLAN タグを付けられ、
eth1経由で物理ネットワークに出ていきます。このインターフェースが接続されている L2 スイッチは、使用される VLAN ID を持つ通信を許可するよう設定する必要があります。このパケットの次のホップも、同じ L2 ネットワーク上になければいけません。GRE ベースのネットワークは、
patch-tunを用いて、patch-intインターフェースのbr-tunトンネルブリッジに渡されます。このブリッジは、各 GRE トンネルの 1 つのポートにも含まれます。つまり、ネットワーク上の各コンピュートノードとネットワークノードに対して 1 つです。ポートの名前は、gre-1から順番に増えていきます。gre-<n>インターフェースとトンネルエンドポイントを一致させることは、おそらく Open vSwitch の状態を見ることになります。# ovs-vsctl show | grep -A 3 -e Port\ \"gre- Port "gre-1" Interface "gre-1" type: gre options: {in_key=flow, local_ip="10.10.128.21", out_key=flow, remote_ip="10.10.128.16"}
この場合、
gre-1が IP 10.10.128.21 からリモートの IP 10.10.128.16 へのトンネルです。これは、このノードのローカルインターフェースと一致します。これらのトンネルは、ホストにおいて通常のルーティングテーブルを使用して、できあがった GRE パケットを中継します。そのため、VLAN カプセル化と異なり、GRE エンドポイントがすべて同じ L2 ネットワークにあるという要件は必要ありません。
br-tunにあるすべてのインターフェースは、Open vSwitch 内部のものです。それらの通信を監視する場合、br-intにあるpatch-tun向けに上で説明したようなミラーポートをセットアップする必要があります。このブリッジで GRE トンネルと内部 VLAN の相互変換が行われます。
ovs-ofctlコマンドを使用することにより、GRE トンネル向けに使用されている内部 VLAN タグを検索します。
興味あるネットワークの
provider:segmentation_idを探します。これは、VLAN ベースのネットワークにおける VLAN ID に使用されるものと同じ項目です。# neutron net-show --fields provider:segmentation_id <network name> +--------------------------+-------+ | Field | Value | +--------------------------+-------+ | provider:network_type | gre | | provider:segmentation_id | 3 | +--------------------------+-------+
この場合、
ovs-ofctl dump-flows br-tunの出力で 0x<provider:segmentation_id>, 0x3 を grep します。# ovs-ofctl dump-flows br-tun|grep 0x3 cookie=0x0, duration=380575.724s, table=2, n_packets=1800, n_bytes=286104, priority=1,tun_id=0x3 actions=mod_vlan_vid:1,resubmit(,10) cookie=0x0, duration=715.529s, table=20, n_packets=5, n_bytes=830, hard_timeout=300,priority=1, vlan_tci=0x0001/0x0fff,dl_dst=fa:16:3e:a6:48:24 actions=load:0->NXM_OF_VLAN_TCI[], load:0x3->NXM_NX_TUN_ID[],output:53 cookie=0x0, duration=193729.242s, table=21, n_packets=58761, n_bytes=2618498, dl_vlan=1 actions=strip_vlan,set_tunnel:0x3, output:4,output:58,output:56,output:11,output:12,output:47, output:13,output:48,output:49,output:44,output:43,output:45, output:46,output:30,output:31,output:29,output:28,output:26, output:27,output:24,output:25,output:32,output:19,output:21, output:59,output:60,output:57,output:6,output:5,output:20, output:18,output:17,output:16,output:15,output:14,output:7, output:9,output:8,output:53,output:10,output:3,output:2, output:38,output:37,output:39,output:40,output:34,output:23, output:36,output:35,output:22,output:42,output:41,output:54, output:52,output:51,output:50,output:55,output:33
ここで、この GRE トンネルに関連する 3 つのフローを見つけられます。1 番目は、このトンネル ID を持つ受信パケットから内部 VLAN ID 1 に変換したものです。2 番目は、MAC アドレス fa:16:3e:a6:48:24 宛のパケットに対する送信ポート 53 番へのユニキャストフローです。3 番目は、内部 VLAN 表現から、すべての出力ポートにあふれ出した GRE トンネル ID に変換したものです。フローの説明の詳細は
ovs-ofctlのマニュアルページを参照してください。前の VLAN の例にあるように、数値ポート ID は、ovs-ofctl show br-tunの出力を検査することにより、それらの名前を付けた表現に対応付けられます。
次に、パケットはネットワークノードで受信されます。L3 エージェントや DHCP エージェントへのすべての通信は、それらのネットワーク名前空間の中のみで参照できます。それらの名前空間の外部にあるすべてのインターフェースを監視することにより、ネットワーク通信を転送している場合でも、ARP のようなブロードキャストパケットのみが表示されます。しかし、ルーターや DHCP アドレスへのユニキャスト通信は表示されません。これらの名前空間の中でコマンドを実行する方法の詳細は、 ネットワーク名前空間への対応 を参照してください。
これとは別に、外部ルーターが同じ VLAN にあれば、ここの示されている L3 エージェントの代わりに外部ルーターを使用するよう、VLAN ベースのネットワークを設定できます。
VLAN ベースのネットワークは、この例にある物理ネットワークインターフェース
eth1においてタグ付きパケットとして受信されます。コンピュートノードでは、このインターフェースがbr-eth1ブリッジのメンバーです。GRE ベースのネットワークは、トンネルブリッジ
br-tunに転送されます。これは、コンピュートノードにおいて GRE インターフェースのように動作します。
次に、何かしらの入力パケットは統合ブリッジ経由で送信されます。繰り返しますが、コンピュートノードと同じようなものです。
そして、パケットが L3 エージェントに到達します。これは実際には、ルーターの名前空間の中にある別の TAP デバイスです。ルーター名前空間は、
qrouter-<router-uuid>という形式の名前です。名前空間の中で ip a を実行することにより、TAP デバイスの名前を表示します。この例では qr-e6256f7d-31 です。# ip netns exec qrouter-e521f9d0-a1bd-4ff4-bc81-78a60dd88fe5 ip a | grep state 10: qr-e6256f7d-31: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN 11: qg-35916e1f-36: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UNKNOWN qlen 500 28: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN
l3-agent のルーターの名前空間にある
qg-<n>インターフェースは、外部ブリッジbr-exにあるeth2デバイス経由で次のホップにパケットを送信します。このブリッジは、br-eth1と同じように作られ、同じ方法で検査できるでしょう。この外部ブリッジも物理ネットワークインターフェースに含まれます。この例では
eth2です。これは、最終的に外部ルーターや送信先に向けた外部ネットワークのパケットを受け取ります。OpenStack ネットワークで動作している DHCP エージェントは、l3-agent と同じような名前空間で動作します。DHCP 名前空間は、
qdhcp-<uuid>という名前を持ち、統合ブリッジに TAP デバイスを持ちます。DHCP の問題のデバッグは、通常この名前空間の中での動作に関連します。
経路上の障害を見つける¶
ネットワーク経路のどこに障害があるかを素早く見つけるには、pingを使います。まずあなたがインスタンス上で、google.comのような外部ホストにpingできるのであれば、ネットワークの問題はないでしょう。
もしそれができないのであれば、インスタンスがホストされているコンピュートノードのIPアドレスへpingを試行してください。もしそのIPにpingできるのであれば、そのコンピュートノードと、ゲートウェイ間のどこかに問題があります。
もしコンピュートノードのIPアドレスにpingできないのであれば、問題はインスタンスとコンピュートノード間にあります。これはコンピュートノードの物理NICとインスタンス vnet NIC間のブリッジ接続を含みます。
最後のテストは、2 つ目のインスタンスを起動して、2 つのインスタンスがお互いに ping できることを確認することです。もしできる場合、問題はコンピュートノードのファイアウォールに関連するものでしょう。
tcpdump¶
ネットワーク問題の解決を徹底的に行う方法のひとつは、 tcpdump です。 tcpdump を使い、ネットワーク経路上の数点、問題のありそうなところから情報を収集することをおすすめします。もし GUI が好みであれば、 Wireshark を試してみてはいかがでしょう。
例えば、以下のコマンドを実行します。
# tcpdump -i any -n -v 'icmp[icmptype] = icmp-echoreply or icmp[icmptype] = icmp-echo'
このコマンドは以下の場所で実行します。
クラウド外部のサーバー
コンピュートノード
コンピュートノード内のインスタンス
例では、この環境には以下のIPアドレスが存在します
Instance
10.0.2.24
203.0.113.30
Compute Node
10.0.0.42
203.0.113.34
External Server
1.2.3.4
次に、新しいシェルを開いて tcpdump の動いている外部ホストへ ping を行います。もし外部サーバーとのネットワーク経路に問題がなければ、以下のように表示されます。
外部サーバー上
12:51:42.020227 IP (tos 0x0, ttl 61, id 0, offset 0, flags [DF],
proto ICMP (1), length 84)
203.0.113.30 > 1.2.3.4: ICMP echo request, id 24895, seq 1, length 64
12:51:42.020255 IP (tos 0x0, ttl 64, id 8137, offset 0, flags [none],
proto ICMP (1), length 84)
1.2.3.4 > 203.0.113.30: ICMP echo reply, id 24895, seq 1,
length 64
コンピュートノード上
12:51:42.019519 IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF],
proto ICMP (1), length 84)
10.0.2.24 > 1.2.3.4: ICMP echo request, id 24895, seq 1, length 64
12:51:42.019519 IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF],
proto ICMP (1), length 84)
10.0.2.24 > 1.2.3.4: ICMP echo request, id 24895, seq 1, length 64
12:51:42.019545 IP (tos 0x0, ttl 63, id 0, offset 0, flags [DF],
proto ICMP (1), length 84)
203.0.113.30 > 1.2.3.4: ICMP echo request, id 24895, seq 1, length 64
12:51:42.019780 IP (tos 0x0, ttl 62, id 8137, offset 0, flags [none],
proto ICMP (1), length 84)
1.2.3.4 > 203.0.113.30: ICMP echo reply, id 24895, seq 1, length 64
12:51:42.019801 IP (tos 0x0, ttl 61, id 8137, offset 0, flags [none],
proto ICMP (1), length 84)
1.2.3.4 > 10.0.2.24: ICMP echo reply, id 24895, seq 1, length 64
12:51:42.019807 IP (tos 0x0, ttl 61, id 8137, offset 0, flags [none],
proto ICMP (1), length 84)
1.2.3.4 > 10.0.2.24: ICMP echo reply, id 24895, seq 1, length 64
インスタンス上
12:51:42.020974 IP (tos 0x0, ttl 61, id 8137, offset 0, flags [none],
proto ICMP (1), length 84)
1.2.3.4 > 10.0.2.24: ICMP echo reply, id 24895, seq 1, length 64
外部サーバーはpingリクエストを受信し、pingリプライを送信しています。コンピュートノード上では、pingとpingリプライがそれぞれ成功していることがわかります。また、見ての通り、コンピュートノード上ではパケットが重複していることもわかるでしょう。なぜなら``tcpdump`` はブリッジと外向けインターフェイスの両方でパケットをキャプチャーするからです。
iptables¶
nova-network か neutron に関わらず、OpenStack Compute は自動的に iptables を管理します。コンピュートノードにあるインスタンスとのパケット転送、Floating IP 通信の転送、セキュリティグループルールの管理など。ルールの管理に加えて、(サポートされる場合) コメントがルールに挿入され、ルールの目的を理解しやすくします。
以下のコメントが、適切にルールセットに追加されます。
送信方向にソース NAT 実行。
一致しない通信のデフォルト破棄ルール。
仮想マシンインスタンスからセキュリティグループチェインへの直接通信。
仮想マシン固有チェインへのジャンプ。
仮想マシンからセキュリティグループチェインへの直接受信。
定義済み IP/MAC ペアからの通信許可。
IP/MAC 許可ルールにない通信の破棄。
DHCP クライアント通信の許可。
仮想マシンによる DHCP スプーフィングの防止。
一致しない通信のフォールバックチェインへの送信。
どの状態にも関連付けられていないパケットの破棄。
既知のセッションに関連付けられたパケットの RETURN チェインへの転送。
RA パケットを許可するための IPv6 ICMP 通信の許可。
iptablesの現在の構成を見るには、以下のコマンドを実行します。
# iptables-save
注釈
もし iptables の構成を変更した場合、次の nova-network や neutron-server の再起動時に前の状態に戻ります。 iptables の管理には OpenStack を使ってください。
nova-network 用データベースにあるネットワーク設定¶
nova-network を用いると、nova データベーステーブルは、いくつかのネットワーク情報を持つテーブルがあります。
fixed_ipsnova に登録されたサブネットで利用可能なIPアドレス。このテーブルは
fixed_ips.instance_uuid列でinstancesテーブルと関連付けられます。floating_ipsCompute に登録された各 Floating IP アドレス。このテーブルは
floating_ips.fixed_ip_id列でfixed_ipsテーブルと関連付けられます。instancesネットワーク特有のテーブルではありませんが、
fixed_ipとfloating_ipを使っているインスタンスの情報を管理します。
これらのテーブルから、Floating IPが技術的には直接インスタンスにひも付けられておらず、固定IP経由であることがわかります。
Floating IP の手動割り当て解除¶
しばしば、 Floating IP を正しく開放しないままインスタンスが終了されることがあります。するとデータベースは不整合状態となるため、通常のツールではうまく開放できません。解決するには、手動でデータベースを更新する必要があります。
まず、インスタンスの UUID を確認します。
mysql> select uuid from instances where hostname = 'hostname';
次に、その UUID から固定 IP のエントリーを探します。
mysql> select * from fixed_ips where instance_uuid = '<uuid>';
関連する Floating IP のエントリーが見つかります。
mysql> select * from floating_ips where fixed_ip_id = '<fixed_ip_id>';
最後に、floating IP を開放します。
mysql> update floating_ips set fixed_ip_id = NULL, host = NULL where
fixed_ip_id = '<fixed_ip_id>';
また、ユーザプールから IP を開放することもできます。
mysql> update floating_ips set project_id = NULL where
fixed_ip_id = '<fixed_ip_id>';
nova-network の DHCP 問題の デバッグ¶
よくあるネットワークの問題に、インスタンスが起動しているにも関わらず、dnsmasq からの IP アドレス取得に失敗し、到達できないという現象があります。 dnsmasq は nova-network サービスから起動される DHCP サーバです。
もっともシンプルにこの問題を特定する方法は、インスタンス上のコンソール出力を確認することです。もし DHCP が正しく動いていなければ、下記のようにコンソールログを参照してください。
$ openstack console log show <instance name or uuid>
もしインスタンスが DHCP からの IP 取得に失敗していれば、いくつかのメッセージがコンソールで確認できるはずです。例えば、 Cirros イメージでは、以下のような出力になります。
udhcpc (v1.17.2) started
Sending discover...
Sending discover...
Sending discover...
No lease, forking to background
starting DHCP forEthernet interface eth0 [ [1;32mOK[0;39m ]
cloud-setup: checking http://169.254.169.254/2009-04-04/meta-data/instance-id
wget: can't connect to remote host (169.254.169.254): Network is
unreachable
インスタンスが正しく起動した後、この手順でどこが問題かを切り分けることができます。
DHCP の問題は dnsmasq の不具合が原因となりがちです。まず、ログを確認し、その後該当するプロジェクト(テナント)の dnsmasq プロセスを再起動してください。 VLAN モードにおいては、 dnsmasq プロセスはテナントごとに存在します。すでに該当の dnsmasq プロセスを再起動しているのであれば、もっともシンプルな解決法は、マシン上の全ての dnsmasq プロセスをkillし、 nova-network を再起動することです。最終手段として、root で以下を実行してください。
# killall dnsmasq
# restart nova-network
注釈
RHEL/CentOS/Fedora の場合は openstack-nova-network を使用しますが、Ubuntu/Debian の場合は nova-network を使用します。
nova-network の再起動から数分後、新たな dnsmasq プロセスが動いていることが確認できるでしょう。
# ps aux | grep dnsmasq
nobody 3735 0.0 0.0 27540 1044 ? S 15:40 0:00 /usr/sbin/dnsmasq --strict-order
--bind-interfaces --conf-file=
--domain=novalocal --pid-file=/var/lib/nova/networks/nova-br100.pid
--listen-address=192.168.100.1 --except-interface=lo
--dhcp-range=set:'novanetwork',192.168.100.2,static,120s
--dhcp-lease-max=256
--dhcp-hostsfile=/var/lib/nova/networks/nova-br100.conf
--dhcp-script=/usr/bin/nova-dhcpbridge --leasefile-ro
root 3736 0.0 0.0 27512 444 ? S 15:40 0:00 /usr/sbin/dnsmasq --strict-order
--bind-interfaces --conf-file=
--domain=novalocal --pid-file=/var/lib/nova/networks/nova-br100.pid
--listen-address=192.168.100.1 --except-interface=lo
--dhcp-range=set:'novanetwork',192.168.100.2,static,120s
--dhcp-lease-max=256
--dhcp-hostsfile=/var/lib/nova/networks/nova-br100.conf
--dhcp-script=/usr/bin/nova-dhcpbridge --leasefile-ro
もしまだインスタンスが IP アドレスを取得できない場合、次は dnsmasq がインスタンスからのDHCPリクエストを見えているか確認します。 dnsmasq プロセスが動いているマシンで、/var/log/syslog を参照し、 dnsmasq の出力を確認します。なお、マルチホストモードで動作している場合は、dnsmasqプロセスはコンピュートノードで動作します。もし dnsmasq がリクエストを正しく受け取り、処理していれば、以下のような出力になります。
Feb 27 22:01:36 mynode dnsmasq-dhcp[2438]: DHCPDISCOVER(br100) fa:16:3e:56:0b:6f
Feb 27 22:01:36 mynode dnsmasq-dhcp[2438]: DHCPOFFER(br100) 192.168.100.3
fa:16:3e:56:0b:6f
Feb 27 22:01:36 mynode dnsmasq-dhcp[2438]: DHCPREQUEST(br100) 192.168.100.3
fa:16:3e:56:0b:6f
Feb 27 22:01:36 mynode dnsmasq-dhcp[2438]: DHCPACK(br100) 192.168.100.3
fa:16:3e:56:0b:6f test
もし DHCPDISCOVER が見つからなければ、 dnsmasq が動いているマシンがインスタンスからパケットを受け取れない何らかの問題があります。もし上記の出力が全て確認でき、かついまだに IP アドレスを取得できないのであれば、パケットはインスタンスから dnsmasq 稼働マシンに到達していますが、その復路に問題があります。
このようなメッセージも確認できるかもしれません。
Feb 27 22:01:36 mynode dnsmasq-dhcp[25435]: DHCPDISCOVER(br100)
fa:16:3e:78:44:84 no address available
これは dnsmasq の、もしくは dnsmasq と``nova-network`` 両方の問題です。(例えば上記では、OpenStack Compute データベース上に利用可能な固定IPがなく、 dnsmasq が IP アドレスを払い出せない問題が発生しています)
もしdnsmasqのログメッセージで疑わしいものがあれば、コマンドラインにてdnsmasqが正しく動いているか確認してください。
$ ps aux | grep dnsmasq
出力は以下のようになります。
108 1695 0.0 0.0 25972 1000 ? S Feb26 0:00 /usr/sbin/dnsmasq
-u libvirt-dnsmasq
--strict-order --bind-interfaces
--pid-file=/var/run/libvirt/network/default.pid --conf-file=
--except-interface lo --listen-address 192.168.122.1
--dhcp-range 192.168.122.2,192.168.122.254
--dhcp-leasefile=/var/lib/libvirt/dnsmasq/default.leases
--dhcp-lease-max=253 --dhcp-no-override
nobody 2438 0.0 0.0 27540 1096 ? S Feb26 0:00 /usr/sbin/dnsmasq
--strict-order --bind-interfaces --conf-file=
--domain=novalocal --pid-file=/var/lib/nova/networks/nova-br100.pid
--listen-address=192.168.100.1
--except-interface=lo
--dhcp-range=set:'novanetwork',192.168.100.2,static,120s
--dhcp-lease-max=256
--dhcp-hostsfile=/var/lib/nova/networks/nova-br100.conf
--dhcp-script=/usr/bin/nova-dhcpbridge --leasefile-ro
root 2439 0.0 0.0 27512 472 ? S Feb26 0:00 /usr/sbin/dnsmasq --strict-order
--bind-interfaces --conf-file=
--domain=novalocal --pid-file=/var/lib/nova/networks/nova-br100.pid
--listen-address=192.168.100.1
--except-interface=lo
--dhcp-range=set:'novanetwork',192.168.100.2,static,120s
--dhcp-lease-max=256
--dhcp-hostsfile=/var/lib/nova/networks/nova-br100.conf
--dhcp-script=/usr/bin/nova-dhcpbridge --leasefile-ro
出力は 3 種類の dnsmasq プロセスを示しています。192.168.122.0 の DHCP サブネット範囲を持つ dnsmasq プロセスが、libvirt に属していますが、無視できます。他の 2 つのプロセスは実際に関連します。1 つは単純なもう一つの親プロセスです。dnsmasq プロセスの引数は、 nova-network に設定した詳細に対応するでしょう。
もし問題が dnsmasq と関係しないようであれば、 tcpdump を使ってパケットロスがないか確認してください。
DHCP トラフィックは UDP を使います。そして、クライアントは 68 番ポートからサーバーの 67 番ポートへパケットを送信します。新しいインスタンスを起動し、機械的にNICをリッスンしてください。トラフィックに現れない通信を特定できるまで行います。 tcpdump で br100 上のポート 67、68 をリッスンするには、こうします。
# tcpdump -i br100 -n port 67 or port 68
また、 ip a や brctl show などのコマンドを使って、インターフェイスが実際にUPしているか、あなたが考えたとおりに設定されているか、正当性を検査をすべきです。
DNS の問題をデバッグする¶
あなたが SSH を使用してインスタンスにログインできるけれども、プロンプトが表示されるまで長い時間 (約1分) を要する場合、DNS に問題があるかもしれません。SSH サーバーが接続元 IP アドレスの DNS 逆引きすること、それがこの問題の原因です。もしあなたのインスタンスで DNS が正しく引けない場合、SSH のログインプロセスが完了するには、DNS の逆引きがタイムアウトするまで待たなければいけません。
DNS問題のデバッグをするとき、そのインスタンスのdnsmasqが動いているホストが、名前解決できるかを確認することから始めます。もしホストができないのであれば、インスタンスも同様でしょう。
DNS が正しくホスト名をインスタンス内から解決できているか確認する簡単な方法は、 host コマンドです。もし DNS が正しく動いていれば、以下メッセージが確認できます。
$ host openstack.org
openstack.org has address 174.143.194.225
openstack.org mail is handled by 10 mx1.emailsrvr.com.
openstack.org mail is handled by 20 mx2.emailsrvr.com.
もしあなたがCirrosイメージを使っているのであれば、"host"プログラムはインストールされていません。その場合はpingを使い、ホスト名が解決できているか判断できます。もしDNSが動いていれば、ping結果の先頭行はこうなるはずです。
$ ping openstack.org
PING openstack.org (174.143.194.225): 56 data bytes
もしインスタンスがホスト名の解決に失敗するのであれば、DNSに問題があります。例えば、
$ ping openstack.org
ping: bad address 'openstack.org'
OpenStack クラウドにおいて、 dnsmasq プロセスは DHCP サーバに加えてDNS サーバーの役割を担っています。 dnsmasq の不具合は、インスタンスにおける DNS 関連問題の原因となりえます。前節で述べたように、 dnsmasq の不具合を解決するもっともシンプルな方法は、マシン上のすべてのdnsmasq プロセスをkillし、 nova-network を再起動することです。しかしながら、このコマンドは該当ノード上で動いているすべてのインスタンス、特に問題がないテナントにも影響します。最終手段として、rootで以下を実行します。
# killall dnsmasq
# restart nova-network
dnsmasq再起動後に、DNSが動いているか確認します。
dnsmasq の再起動でも問題が解決しないときは、 tcpdump で問題がある場所のパケットトレースを行う必要があるでしょう。 DNS サーバーは UDP ポート 53 番でリッスンします。あなたのコンピュートノードのブリッジ (br100 など) 上で DNS リクエストをチェックしてください。コンピュートノード上にて、 tcpdump でリッスンを開始すると、
# tcpdump -i br100 -n -v udp port 53
tcpdump: listening on br100, link-type EN10MB (Ethernet), capture size 65535 bytes
インスタンスに SSH ログインして、 ping openstack.org を試すと、以下のようなメッセージが確認できるでしょう。
16:36:18.807518 IP (tos 0x0, ttl 64, id 56057, offset 0, flags [DF],
proto UDP (17), length 59)
192.168.100.4.54244 > 192.168.100.1.53: 2+ A? openstack.org. (31)
16:36:18.808285 IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF],
proto UDP (17), length 75)
192.168.100.1.53 > 192.168.100.4.54244: 2 1/0/0 openstack.org. A
174.143.194.225 (47)
Open vSwitch のトラブルシューティング¶
前の OpenStack Networking の例で使用されていたように、Open vSwitch は、オープンソースの Apache 2.0 license にてライセンスされている、完全な機能を持つマルチレイヤー仮想スイッチです。ドキュメント全体は プロジェクトの Web サイト <http://www.openvswitch.org/>`_ にあります。実際のところ、前述の設定を用いた場合、最も一般的な問題は、必要となるブリッジ (``br-int 、 br-tun 、 br-ex) が存在し、それらに接続される適切なポートを持つことを確認することです。
Open vSwitch ドライバーは、これを自動的に管理すべきです。また、一般的に管理します。しかし、 ovs-vsctl コマンドを用いて、これを手動で実行する方法を知ることは有用です。このコマンドは、ここで使用している以上に、数多くのサブコマンドがあります。完全な一覧は、マニュアルページを参照するか、 ovs-vsctl --help を使用してください。
ovs-vsctl list-br を使用して、システムにあるブリッジを一覧表示します。この例は、内部ブリッジと統合ブリッジを持つコンピュートノードを表します。VLAN ネットワークが eth1 ネットワークインターフェース経由でトランクされます。
# ovs-vsctl list-br
br-int
br-tun
eth1-br
物理インターフェースより内側に取り組むと、ポートとブリッジのチェインを確認できます。まず、物理インターフェース eth1 と仮想インターフェース phy-eth1-br を含むブリッジ eth1-br です。
# ovs-vsctl list-ports eth1-br
eth1
phy-eth1-br
次に、内部ブリッジ br-int は int-eth1-br を持ちます。この int-eth1-br は、 phy-eth1-br とペアになり、前のブリッジ patch-tun で示された物理ネットワークに接続されます。この patch-tun は、GRE トンネルブリッジを接続するために使用され、システムにおいて現在動作しているインスタンスに接続される TAP デバイスです。
# ovs-vsctl list-ports br-int
int-eth1-br
patch-tun
tap2d782834-d1
tap690466bc-92
tap8a864970-2d
トンネルブリッジ br-tun は、GRE 経由で接続するお互いの接続相手のために patch-int インターフェースと gre-<N> インターフェース、クラスター内で各コンピュートノードとネットワークノードのためのものを含みます。
# ovs-vsctl list-ports br-tun
patch-int
gre-1
.
.
.
gre-<N>
これらのリンクのどれかが存在しない、または誤っている場合、設定エラーを暗示しています。ブリッジは ovs-vsctl add-br で追加できます。ポートは ovs-vsctl add-port でブリッジに追加できます。これらを手動で実行することはデバッグに有用ですが、維持することを意図した手動の変更が設定ファイルの中に反映されなければいけません。
ネットワーク名前空間への対応¶
Linux のネットワーク名前空間は、ネットワークサービスが、重複する IP アドレス範囲を持つ、複数の独立した L2 ネットワークをサポートするために使用する、カーネルの機能です。この機能のサポートが無効化されている可能性がありますが、デフォルトで有効になっています。お使いの環境で有効化されている場合、ネットワークノードが DHCP エージェントと L3 エージェントを独立した名前空間で動作します。ネットワークインターフェース、それらのインターフェースにおける通信は、デフォルトの名前空間で見えなくなります。
ip netns を実行して、名前空間を使用しているかどうかを確認します。
# ip netns
qdhcp-e521f9d0-a1bd-4ff4-bc81-78a60dd88fe5
qdhcp-a4d00c60-f005-400e-a24c-1bf8b8308f98
qdhcp-fe178706-9942-4600-9224-b2ae7c61db71
qdhcp-0a1d0a27-cffa-4de3-92c5-9d3fd3f2e74d
qrouter-8a4ce760-ab55-4f2f-8ec5-a2e858ce0d39
qrouter-<router_uuid> という名前の L3 エージェントのルーター名前空間および DHCP エージェントの名前空間は、 qdhcp-<net_uuid> という名前です。この出力は、DHCP エージェントを実行している 4 つのネットワークを持つネットワークノードを表しています。また、1 つは L3 エージェントルーターも実行しています。作業する必要のあるネットワークを理解することは重要です。既存のネットワークおよび UUID の一覧は、管理クレデンシャルを持って openstack network list を実行することにより得られます。
作業する必要のある名前空間を決めると、コマンドの前に ip netns exec <namespace> を付けることにより、前に言及したデバッグツールをすべて使用できます。例えば、上で返された最初の qdhcp 名前空間に存在するネットワークインターフェースを参照する場合、このように実行します。
# ip netns exec qdhcp-e521f9d0-a1bd-4ff4-bc81-78a60dd88fe5 ip a
10: tape6256f7d-31: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN
link/ether fa:16:3e:aa:f7:a1 brd ff:ff:ff:ff:ff:ff
inet 10.0.1.100/24 brd 10.0.1.255 scope global tape6256f7d-31
inet 169.254.169.254/16 brd 169.254.255.255 scope global tape6256f7d-31
inet6 fe80::f816:3eff:feaa:f7a1/64 scope link
valid_lft forever preferred_lft forever
28: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
ここから、そのネットワークにある DHCP サーバーが tape6256f7d-31 デバイスを使用していて、IP アドレス 10.0.1.100 を持つことを確認します。アドレス 169.254.169.254 を確認することにより、dhcp-agent が metadata-proxy サービスを実行していることも確認できます。この章の前の部分で言及したコマンドは、すべて同じ方法で実行できます。 bash などのシェルを実行して、名前空間の中で対話式セッションを持つこともできます。後者の場合、シェルを抜けることにより、最上位のデフォルトの名前空間に戻ります。
Assign a lost IPv4 address back to a project¶
管理者クレデンシャルを使用して、失われた IP アドレスがまだ利用できることを確認します。
# openstack server list --all-project | grep 'IP-ADDRESS'
Create a port:
$ openstack port create --network NETWORK_ID PORT_NAME
IPv4 アドレスを持つ新しいポートを更新します。
# openstack subnet list # neutron port-update PORT_NAME --request-format=json --fixed-ips \ type=dict list=true subnet_id=NETWORK_ID_IPv4_SUBNET_ID \ ip_address=IP_ADDRESS subnet_id=NETWORK_ID_IPv6_SUBNET_ID # openstack port show PORT-NAME
Tools for automated neutron diagnosis¶
easyOVS is a useful tool when it comes to operating your OpenvSwitch bridges and iptables on your OpenStack platform. It automatically associates the virtual ports with the VM MAC/IP, VLAN tag and namespace information, as well as the iptables rules for VMs.
Don is another convenient network analysis and diagnostic system that provides a completely automated service for verifying and diagnosing the networking functionality provided by OVS.
Additionally, you can refer to neutron client for more options.
